こんにちは。
今回のテーマは「勾配法(Gradient Method)」です。これは関数の極値を求める手法です。いきなりですがその多種多様な具体的手法をみてみましょう。
- Gradient descent (ascent)
- Batch gradient descent
- Stochastic gradient descent
- Mini-batch gradient descent
- Momentum
- AdaGrad
- Adam
- Adadelta
- RMSprop
他にも「ここ」にいっぱいあります。僕の中の最新はAdamだったんですが「ここ」をみると改良されたのかな?まあ置いておいて。ところで
そもそも「勾配」ってなんや?
って思いませんか?僕も初めの方は無意識で勾配を扱っていました。勾配の定義をまず確認しましょう。
ベクトル解析におけるスカラー場の勾配(こうばい、英: gradient; グラディエント)は、各点においてそのスカラー場の変化率が最大となる方向への変化率の値を大きさにもつベクトルを対応させるベクトル場である。簡単に言えば、任意の量の空間における変位を、傾きとして表現(例えば図示)することができるが、そこで勾配はこの傾きの向きや傾きのきつさを表している。 (from wiki)
わかりずらい!シンプルに言うと関数の変化率が最も大きくなる方向を勾配ベクトル(勾配)と言います。
証明はテイラー展開すれば簡単にできます。テイラー展開を少しだけおさらいすると局所的に関数を見たいときに使うんでしたね。厳密な証明はググれば山ほど出てくるのでここではメチャ雑に示します。
![\[f(x + \delta) \approx f(x) + ( \nabla f ) \delta \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-711cee2825df8a38489458a95bbc0200_l3.png "Rendered by QuickLaTeX.com")
![\[( \nabla f ) \delta = |\nabla f | |\delta| \cos(\theta) \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-55def500241883862c814ccfd4220222_l3.png "Rendered by QuickLaTeX.com")
 で
で は最大化されます。(ちなみに、
は最大化されます。(ちなみに、 は微量を意味します。)つまり
は微量を意味します。)つまり と
と が平行の時ですね。この時関数が最も大きく変化します。
が平行の時ですね。この時関数が最も大きく変化します。
実際に計算するときは各変数ごとに偏微分すればいいです、つまり とすると
とすると
![\[\nabla f = \left( \frac{\partial f}{\partial x_1} , \frac{\partial f}{\partial x_2} , \frac{\partial f}{\partial x_3} \right) \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-94a40d5ea4c3c9d66975a1ef7f9de893_l3.png "Rendered by QuickLaTeX.com")
あ、 、この記号は勾配を表します。例えば一変数の関数だとその勾配は傾きに等しくなりますね。
、この記号は勾配を表します。例えば一変数の関数だとその勾配は傾きに等しくなりますね。
では勾配と言うものがわかったので
THE 勾配法
行ってみましょう。勾配法とは目的関数を最適化するための局所解を見つける手法のことです。簡単なイメージを持ってもらうためにしたの図を用意しました。
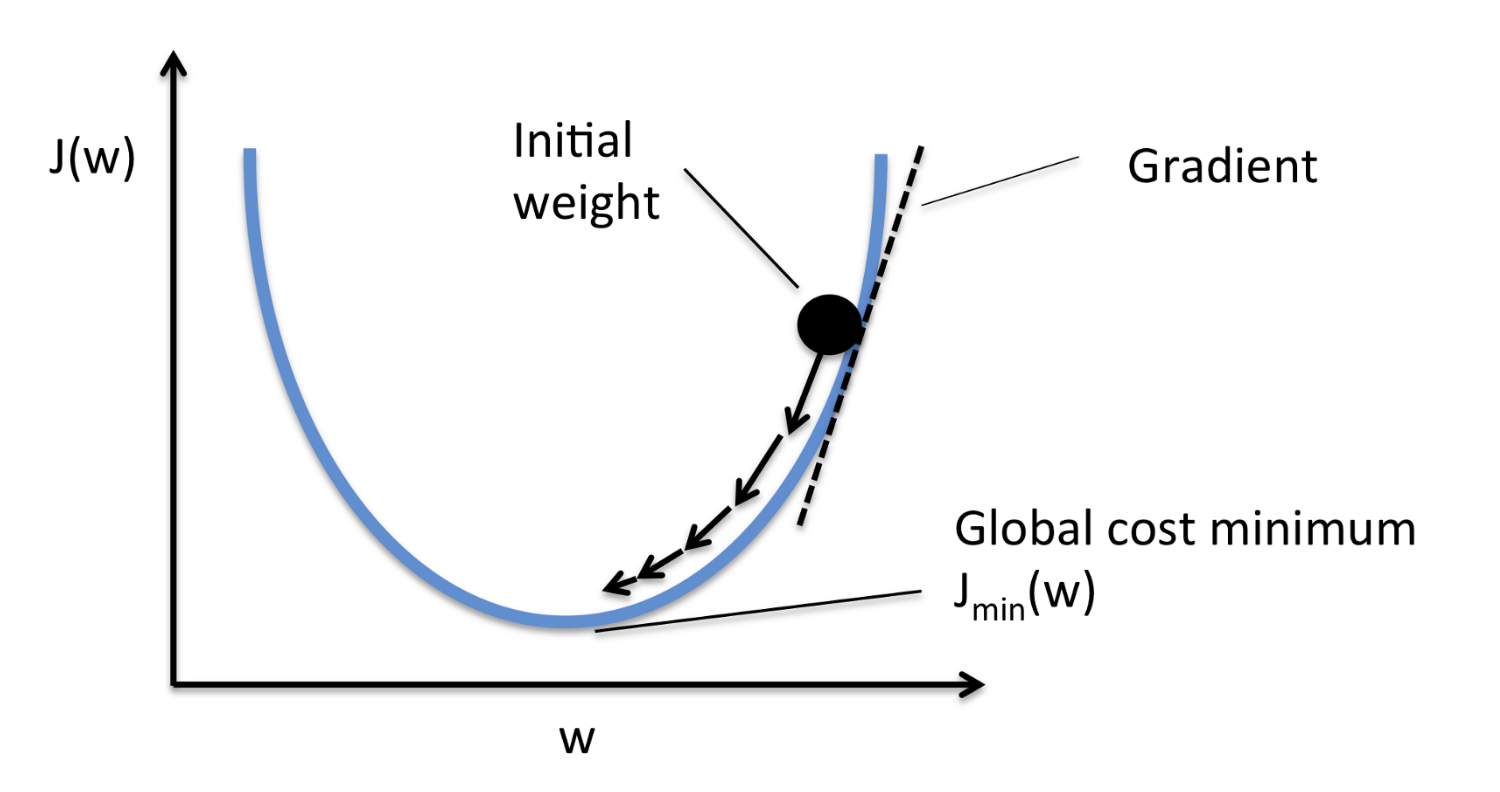
勾配(gradient)を使って関数の極小値・極大値を見つける方法です。ニュートン法とちょっと似てます。式で書くと次のようになります。 はn回目の移動時のxの値とします。(乗数ではありません。)
はn回目の移動時のxの値とします。(乗数ではありません。)
![\[x^{n+1} = x^n \pm \eta \nabla f(x^n) \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-e90f92c149a8f19c75c7ccbec4fe2582_l3.png "Rendered by QuickLaTeX.com")
勾配が関数を最大化する方向であることに注意すると。 は最大化する際に使います、なのでgradient ascentと書きます。一方、
は最大化する際に使います、なのでgradient ascentと書きます。一方、 は最小化する際に使います。gradient descentと書きます。普通はdescentです。ところで
は最小化する際に使います。gradient descentと書きます。普通はdescentです。ところで (イータ)についてですがこれは学習率といわれるものです。xの動き具合を決定します。これについては次の図をみてみましょう。
(イータ)についてですがこれは学習率といわれるものです。xの動き具合を決定します。これについては次の図をみてみましょう。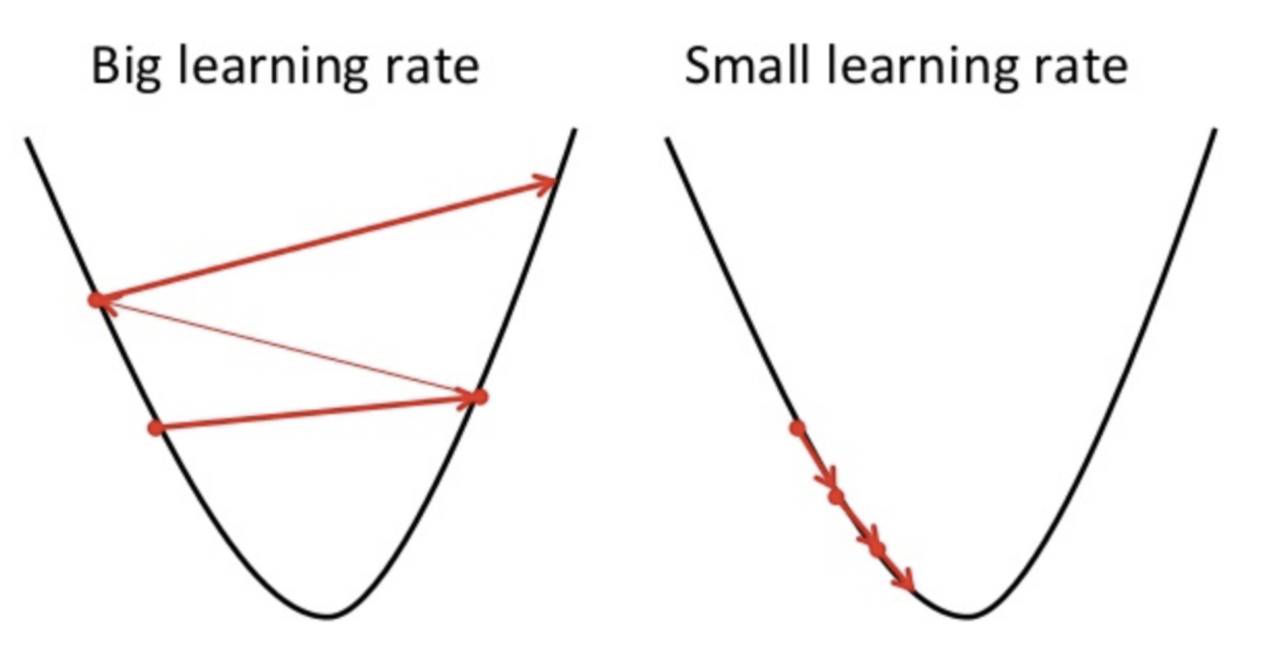
がデカイと動く幅が大きくなるので左の図のようになります。一方、小さすぎると最適解までにたくさん移動する必要があります。
上の図は一変数関数の場合のイメージ図でした。実際は多変数関数を扱うことが多いのでもう一つ2変数関数の場合のイメージ図を見てみましょう。
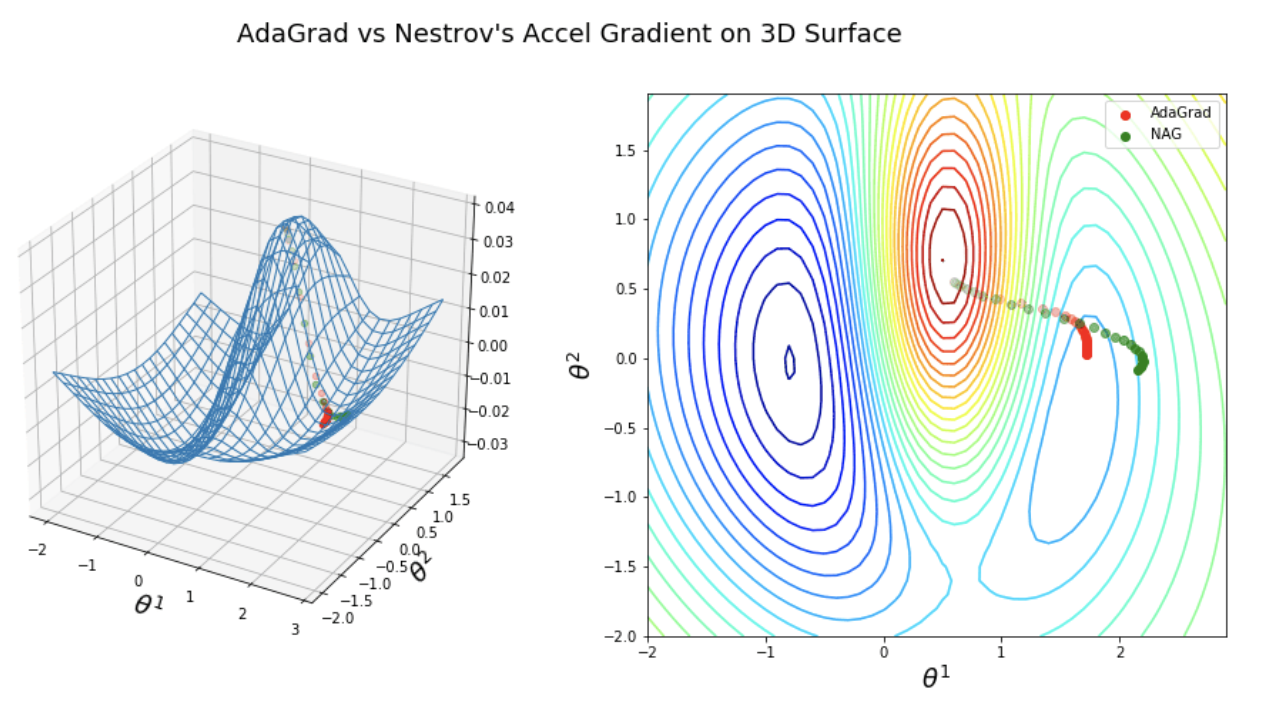
左のplotを等高線で表したものが右の図になります。機械学習では等高線の図は頻繁に見るので慣れてない方は慣れた法がいいです。赤い点と緑の点が異なる勾配法による最適解の軌跡です。ほんとは左の方がこの図だと最適解なんですが右のくぼみに進んでいますね。
数学ちっくな人はこの数列について収束するのか、と疑問を持った人もいるでしょう。
:http://www.stat.cmu.edu/~ryantibs/convexopt-F13/scribes/lec6.pdf
:https://perso.telecom-paristech.fr/rgower/pdf/M2_statistique_optimisation/grad_conv.pdf
例えばこことかに書かれているので興味がある方は読んでみてください。ニュートン法の時の証明結構めんどうだったのでたぶんこっちも結構ヤバそう。。。。。
とりあえず今回で勾配法が何かを理解できたと思います。次回はがっつりコード書きましょう!
引用: