本日はロジスティック回帰の実装をやっていこうと思います。といっても非常に簡単なニューラルネットなのでやらなくてもいいかなと思ったのですが、いきなりSoftmaxを実装するのもアレなのでまずは簡単なこちらからやっていこうと思います。
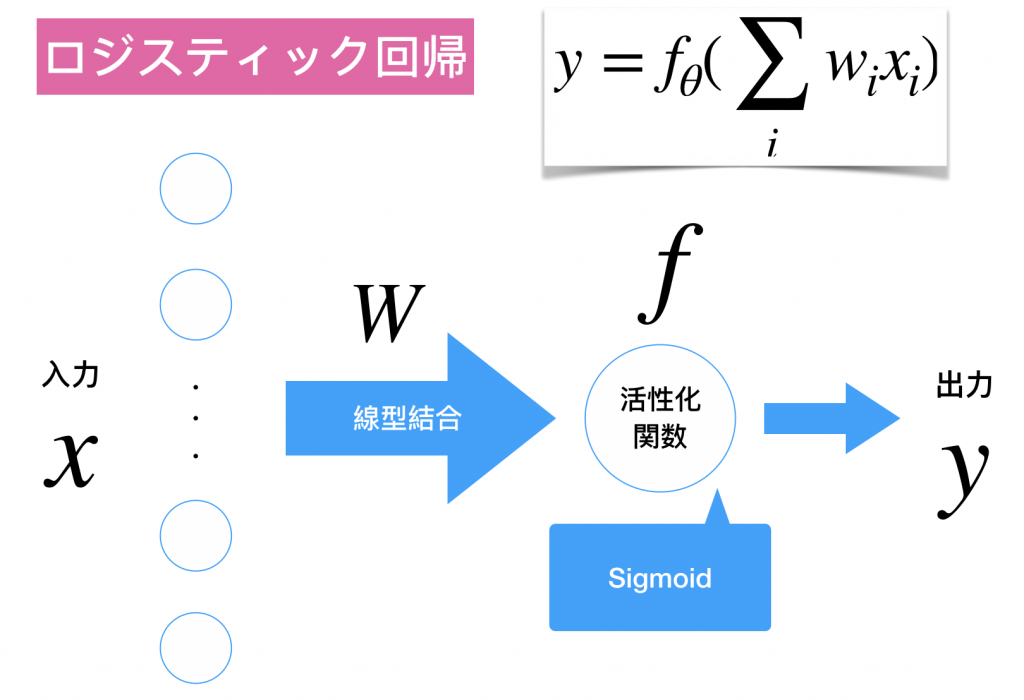
ロジスティック回帰とは?
教師あり学習、2値分類を確率の出力で行います。具体的には閾値を自分で設けます。ロジスティックの場合は0.5だと思います。つまり、シグモイドの出力に対してが0.5以上ならラベル1、0.5未満ならラベル2を振り与えて2値分類を行うわけです。また、これを多値分類に拡張したものがソフトマックスになります。数式導出
まずはシグモイド関数について ![\[\phi(z) = \frac{1}{ 1 + \mathrm{e}^{-z} }\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-b0bcce06a26c7df551bf3e115c6791f6_l3.png "Rendered by QuickLaTeX.com")
![\[\frac{d \phi(z)}{dz} = \frac{d}{dz}\frac{1}{ 1 + \mathrm{e}^{-z} }\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-22648761252ceb28ba8de14fa0305c9f_l3.png "Rendered by QuickLaTeX.com")
![\[= \frac{ \mathrm{e}^{-z} }{ (1 + \mathrm{e}^{-z})^2 } = \frac{1}{(1 + \mathrm{e}^{-z})}( 1 - \frac{1}{(1 + \mathrm{e}^{-z})}) = \phi(z)( 1 - \phi(z))\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-4f122577d9a7fc1d87306ea75555d4c5_l3.png "Rendered by QuickLaTeX.com")
![\[\sum_{i = 1}^{m}\left ( y_i \log\phi_i + (1 - y_i)\log(1 - \phi_i) \right)\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-62c4418dc108800ca92c8ab769178b99_l3.png "Rendered by QuickLaTeX.com")
 が確率である出力、
が確率である出力、 が2値(0,1)つまりラベルの値です。
が2値(0,1)つまりラベルの値です。
![\[Likelihood = \prod_{i=1}^{N} \phi_{i}^{y_{i}}\left(1-\phi_{i}\right)^{\left(1-y_{i}\right)}\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-ca5824219ce384e74d95cda87d175696_l3.png "Rendered by QuickLaTeX.com")
 なのでチェーンルールを用いて(
なのでチェーンルールを用いて( )
)
![\[\frac{\partial J(w)}{\partial w_j} = \frac{\partial}{\partial w_j} - \sum_{i = 1}^{N}[y_i \log\phi_i + (1 - y_i)\log(1 - \phi_i)]\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-589df1f753ddda7a6c37d5e35c173211_l3.png "Rendered by QuickLaTeX.com")
![\[= - \sum_{i = 1}^{N}[y_i\frac{\partial\log\phi_i}{\partial\phi_i}\frac{\partial\phi_i}{\partial z_i}\frac{\partial z_i}{\partial w_j} + (1 - y_i)\frac{\partial\log(1 - \phi_i)}{\partial\phi_i}\frac{\partial\phi_i}{\partial z_i}\frac{\partial z_i}{\partial w_j}]\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-c89b2ca2a6d61442390c07c3b7a4e0f0_l3.png "Rendered by QuickLaTeX.com")
![\[= -\sum_{i = 1}^{N}[y_i\frac{1}{\phi_i}\phi_i(1 - \phi_i)x_{ij} + (1 - y_i)\frac{-1}{(1 - y_i)}\phi_i(1 - \phi_i)x_{ij}]\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-3d49504949ed50fc53a815ac32e4c6e1_l3.png "Rendered by QuickLaTeX.com")
![\[= -\sum_{i = 1}^{N}(y_i - \phi_i)x_{ij}\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-12ba33d7face75dc6b6efe0e92ecd5a2_l3.png "Rendered by QuickLaTeX.com")
![\[\Delta w_j = -\eta(-\sum_{i = 1}^{m}(y_i - \phi_i)x_{ij})\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-fd0fc900b4f7be5419d90e3061acb330_l3.png "Rendered by QuickLaTeX.com")
![\[w_j := w_j + \Delta w_j\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-bde32bb5d093829f0189554f2b31ef12_l3.png "Rendered by QuickLaTeX.com")