今回はたまに聞くであろうGLM、すなわち、一般化線形回帰についてです。回帰といえば今まで線形回帰とかちょろっとやりました。せっかくなので回帰についてちょっとだけ復習してから本題に入りましょう。
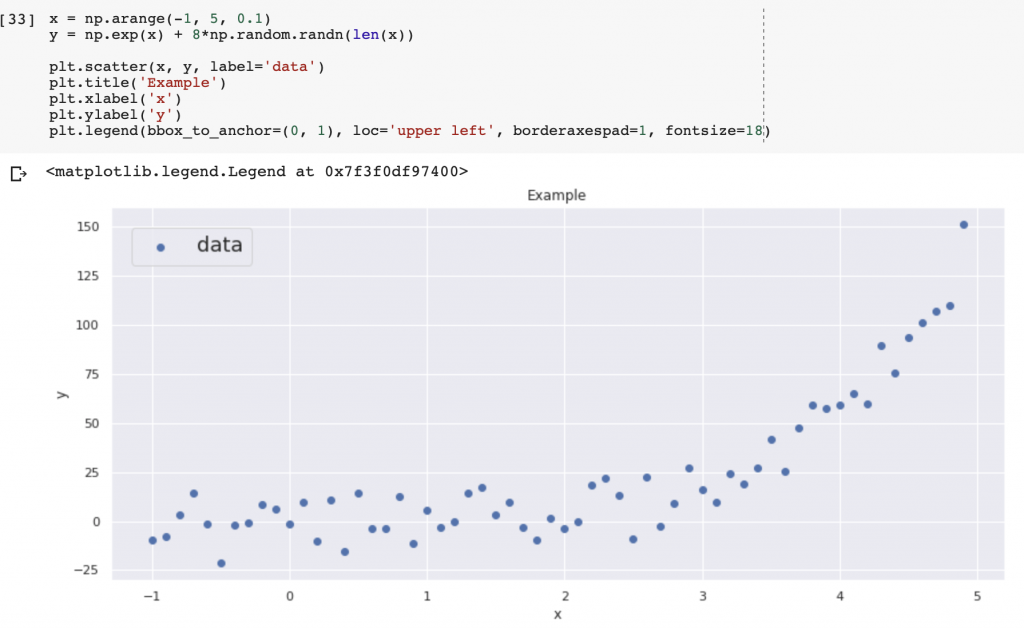
- データが線形ではないとき
- 誤差が
 でない
でない  がカテゴリカルとかだったら
がカテゴリカルとかだったら

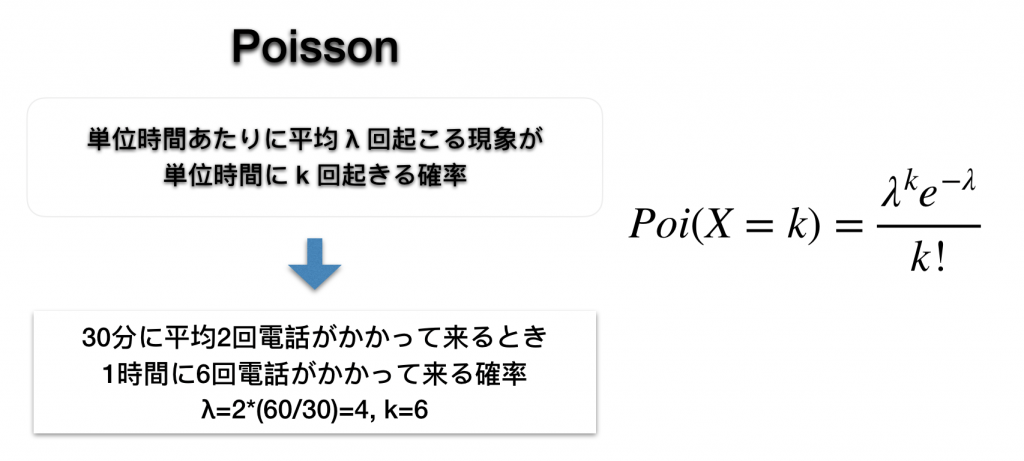
- 線形予測子
- リンク関数
- 確率分布
- 説明変数の線形モデル
- 線形モデルに移す関数
- 目的変数の従う分布

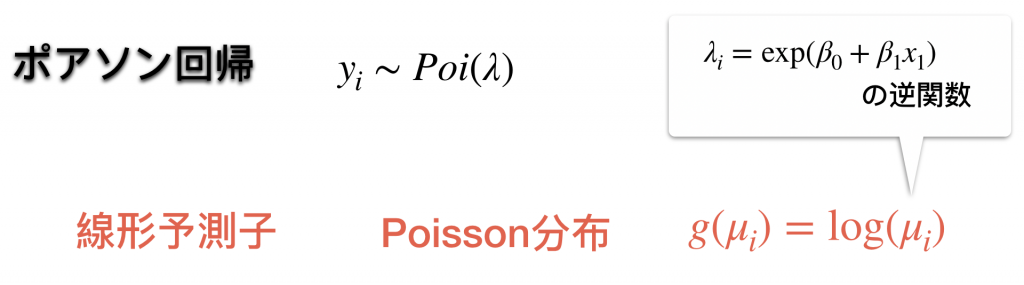
 を
を に食わせることで指数関数を用いてモデルを構成しています。線形予測子を得るためにはを外せばいいので
に食わせることで指数関数を用いてモデルを構成しています。線形予測子を得るためにはを外せばいいので つまり対数がリンク関数になることがわかります。言い換えれば、
つまり対数がリンク関数になることがわかります。言い換えれば、 と単純にモデリングしてしまうと目的変数が正規分布に従わないせいで誤差が大きくなってしまいます。それを避けるためにリンク関数により
と単純にモデリングしてしまうと目的変数が正規分布に従わないせいで誤差が大きくなってしまいます。それを避けるためにリンク関数により と変形していわば補正をかけます。(
と変形していわば補正をかけます。( が平均
が平均 に従うポアソン分布から生成されたと仮定します)
に従うポアソン分布から生成されたと仮定します)
これを用いようとするとPythonよりもRがメジャーな選択肢になりますが、僕はPython派なのでこっちを使います。以下がコードになります。
でわ