前回、モデルを選択する基準のところで情報量基準という言葉をちょこっと出して、そのままスルーしました。しかし、データ分析においては重要なのでとりあえずその基礎くらいは知っておきましょう。ちなみにコードを書く際にパラメータ選択させられることもあります。
ではそもそも情報量基準とはなんなのか?

では、ここで出る問題は
errorが小さければいいのか? ということです。以前触れましたが、モデルは学習の際に、underfittingやoverfittingを引き起こします。これはパラメータ数によって起こることが多いです。これは明らかですよね。例えば、多項式回帰の字数を増やしまくるとそのモデルはグニャグニャに曲がってデータにフィットしようとしますよね。もちろんfitするということは例えば誤差二乗和を計算すると必ず字数の増加に伴いそれは減少します。しかしこれは、上述の通りoverfittingではないのか?という問題です。
では、問題をまとめると
- 誤差(error)を減らしたい
- 過学習は避けたい
2種類あるねんから使い分けは?ってなりますよね。これについては非常に難しい議論のようです。 上のリンクによると結論としては
- AICとBICを両方使う
- セットで値が小さいモデルを選ぶ
AIC tries to select the model that most adequately describes an unknown, high dimensional reality. This means that reality is never in the set of candidate models that are being considered. On the contrary, BIC tries to find the TRUE model among the set of candidates.ここで重要な点は
- AICはモデルが真である仮定をしてない
- BICは真のモデルがあると仮定して計算してる
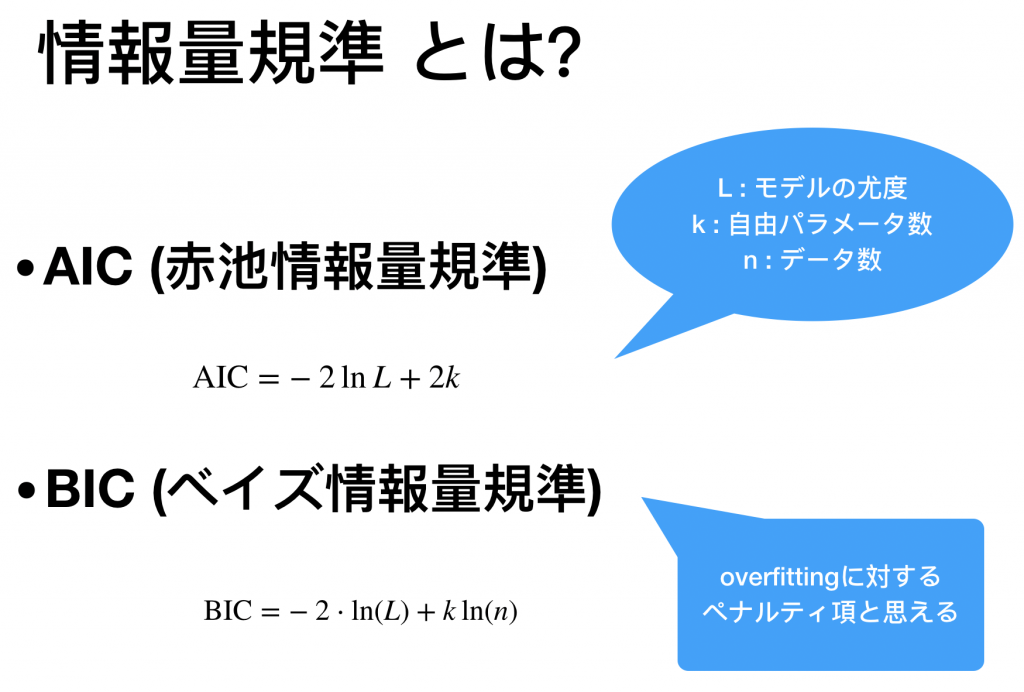
![\[\mathrm{AIC}=-2 \ln L+2 k\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-c1c90c3f232e622f27ca268bfdf92d69_l3.png "Rendered by QuickLaTeX.com")
![\[\mathrm{BIC}=-2 \cdot \ln (L)+k \ln (n)\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-226a4e3b96561d5243789b80d438560f_l3.png "Rendered by QuickLaTeX.com")
 以上になるとBICの方が強くペナルティが反映されることがわかります。なので直感的にはBICはより厳しい検査基準と考えられそうです。
以上になるとBICの方が強くペナルティが反映されることがわかります。なので直感的にはBICはより厳しい検査基準と考えられそうです。
もう少し、深入りしてみます。
上で、導出の背景と言いましたが次の論文を見てみると AICはKLの最小化を目的として導出されました。一方でBICは事後分布の最大化を目的として導出されました。とはいえ、やはりどちらがいいかはわからないですね、、どっちか選べって言われると僕ならAICですかね。ちなみにKLを知らない人のためにちょこっとだけ説明すると
![\[D_{\mathrm{KL}}(P | Q)=\int_{-\infty}^{\infty} p(x) \log \left(\frac{p(x)}{q(x)}\right) dx\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-483f7ef9b6df1eee94063f72d1ff5b7c_l3.png "Rendered by QuickLaTeX.com")

![\[ \begin{aligned} D_{\mathrm{KL}}(P | Q) &=\sum_{x \in \mathcal{X}} P(x) \ln \left(\frac{P(x)}{Q(x)}\right) \ &=0.36 \ln \left(\frac{0.36}{0.33}\right)+0.48 \ln \left(\frac{0.48}{0.333}\right)+0.16 \ln \left(\frac{0.16}{0.33}\right) \ &=0.0852 \end{aligned}\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-e5b4055643b65d56857f7bbd20fe4261_l3.png "Rendered by QuickLaTeX.com")
こんな感じで計算します。2つの正規分布間のKLの計算とかやってみるといい練習になると思います。ここで重要なのが1つ。先ほどKLを距離と言いましたが、
KLは距離じゃない
数学をやってる人なら次の例でわかってくれると思います。上の計算は でした、一方で
でした、一方で を計算すると
を計算すると
![\[\begin{aligned} D_{\mathrm{KL}}(Q | P) &=\sum_{x \in \mathcal{X}} Q(x) \ln \left(\frac{Q(x)}{P(x)}\right) \ &=0.33 \ln \left(\frac{0.33}{0.36}\right)+0.33 \ln \left(\frac{0.33}{0.48}\right)+0.33 \ln \left(\frac{0.33}{0.16}\right) \ &=0.0974 \end{aligned}\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-4b46522405af4abf90523eaf7dc466f1_l3.png "Rendered by QuickLaTeX.com")
KLについて話始めるととんでもなく長くなるのでまた別の記事にして最後にコードを簡単に眺めて終わりましょう。