こんちには。良いバックパックがほしい、そんな日々が続きます。
僕は機械学習を勉強してきていろんなアルゴリズムを使ってきました。その都度いろいろなデータ触れてきました。
そもそもデータをそのままアルゴリズムに突っ込むのは正しいのか?
たとえばPCAの場合データの平均を0にしてからPCAにかける必要があります。
ところでデータは不完全な形でやってきます。今回は次のような車のデータを考えます。
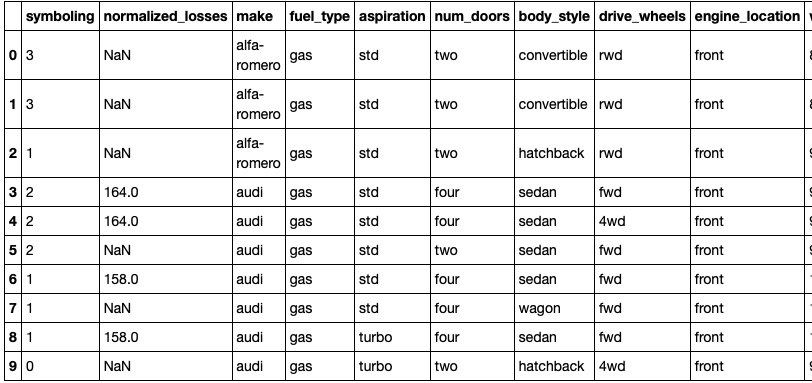
みての通り「文字」「NaN」が混在しています。まずはこれをどうにかする必要があります。対処法は主に次の3パターンかと思います。
LabelEncorder
例えば[dog,cat,dog,mouse,cat]を![[1,2,1,3,2]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-b0d2442501c1daaa4f9575a6145d9b8e_l3.png "Rendered by QuickLaTeX.com") に変換する
に変換する
OneHotEncorder
例えばdog cat monkey dogの4つのデータを[dog, cat, monkey]で表しそれぞれ
![\[[1,0,0], [0,1,0], [0,0,1],[1,0,0]\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-62d2e8d5204bea1028a3b9f0c6bc0473_l3.png "Rendered by QuickLaTeX.com")
の4つにします
LabelBinarizer
OneHotEncorderとほぼ同じ。
さて、本題のデータの前処理なんですが、
- 標準化(standardization)
- 正規化(normalization)
の2種類がメインです。これらの手法をスケーリングといいます。重要なのは違いと必要性ですがその前に定義をみてみましょう。
標準化
![\[ x' = \frac{ x - \mu }{ \sigma } \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-f22762a4c30d5726d1f6bf90f7dd0add_l3.png "Rendered by QuickLaTeX.com")
ただし は平均、分散とする。
は平均、分散とする。
こうすると平均 、分散
、分散 の分布へと変換されます。
の分布へと変換されます。
正規化
![\[ x' = \frac{ x - min }{ max - min } \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-ef63717954aa33060a7efad3b4824eaa_l3.png "Rendered by QuickLaTeX.com")
ただし はデータの最大値、最小値とする。
はデータの最大値、最小値とする。
こうすると新たなデータは![[0,1]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-25b6d943ab489c05a3dbd5ea29087a48_l3.png "Rendered by QuickLaTeX.com") へとスケーリングされます。標準化と違い範囲が固定されるわけではありません。
へとスケーリングされます。標準化と違い範囲が固定されるわけではありません。
で、なんでスケーリングする必要があんの?
もちろんです。
スケーリングなんかせんでもいい
という場合ももちろんあります。例えば、生徒会長を決めるための投票データは「支持する」or「支持しない」のバイナリになります。この場合スケーリングをする必要がないのは明らかでしょう。他には男女別の五教科の点数のデータを分析する際、僕は前処理をする必要性を感じません。なぜならデータの範囲は![[0,100]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-715f49efbf5d818d0be2dd96a575b180_l3.png "Rendered by QuickLaTeX.com") ですし、数値がめちゃめちゃ大きいわけでもないからです。
ですし、数値がめちゃめちゃ大きいわけでもないからです。
では、いつスケーリングやねん
これは正直難しい問題だと思います。なにを分析したいのかという状況・目的に大きく左右されると思います。ですが、冒頭でも言ったようにPCAなど特定のアルゴリズムは特定の前処理を必要とします。
僕の経験上、正規化よりも標準化の方がポピュラーです。というか僕は正規化はしたことないです。理由としては標準化にはセンタリングが含まれるからです。また、そもそも世の中のほとんどデータは正規分布に従っているんです。IQのデータとか身長とか標高でさえ正規分布に従うようです。加えて数学の世界にはいい定理があります。「大数の法則」と「中心極限定理」です。
- 大数の法則: データ超多かったら、その分布の真の平均と実測値の平均が一致!!
- 中心極限定理: データ超多かったら、正規分布に従うと思ってOK!!
これらも標準化がポピュラーな理由の1つでしょう。(1の証明は簡単、マルコフとチェビシェフの不等式を使う)
では次にスケーリングのメリットについてです。1つは学習速度でしょう。次の図をみてください。
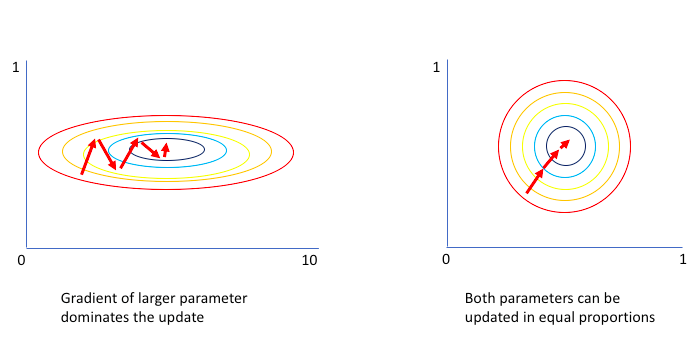
各軸でデータの範囲が大きく異なる場合、図左のように学習が遅くなることがあります。一方で右図はスラリと学習できています。これより勾配法を使うアルゴリズム
- ロジスティック回帰/ソフトマックス回帰
- ニューラルネットワーク/SVM
とかは恩恵を受けるでしょう。
他にはK-meansは一般にはユークリッド距離を用いてクラスタリングします。この際、各特徴を同じ程度重要視して距離を測りたい場合は標準化は効果を発揮するでしょう。(一方、マハラノビス距離は特徴量ごとに距離に重み付けする)
しかし、やはり簡単な問題ではないので何が目的か何をしたいのかを明確にして使い分ける必要がありそうですね。。ここでは標準化・正規化の2つでしたが無相関化(独立主成分分析)などもあります。
最後に簡単な実装を載せておきます。
READ MORE
- https://www.jeremyjordan.me/batch-normalization/
- https://stats.stackexchange.com/questions/41704/how-and-why-do-normalization-and-feature-scaling-work
- https://www.kaggle.com/rtatman/data-cleaning-challenge-scale-and-normalize-data
- https://towardsdatascience.com/encoding-categorical-features-21a2651a065c
- http://mlr.cs.umass.edu/ml/datasets/Automobile