こんにちは、本日はとりあえず実装をする前に、パパッとデータの確認です。
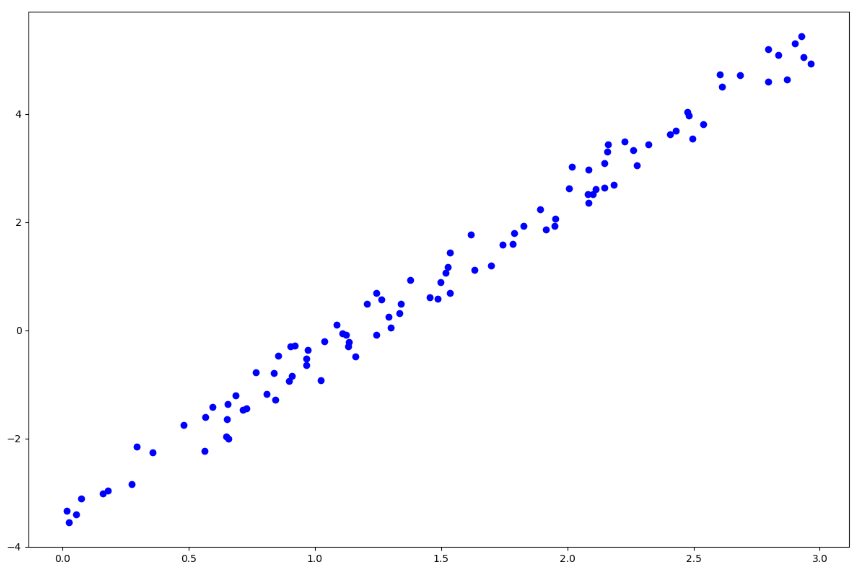
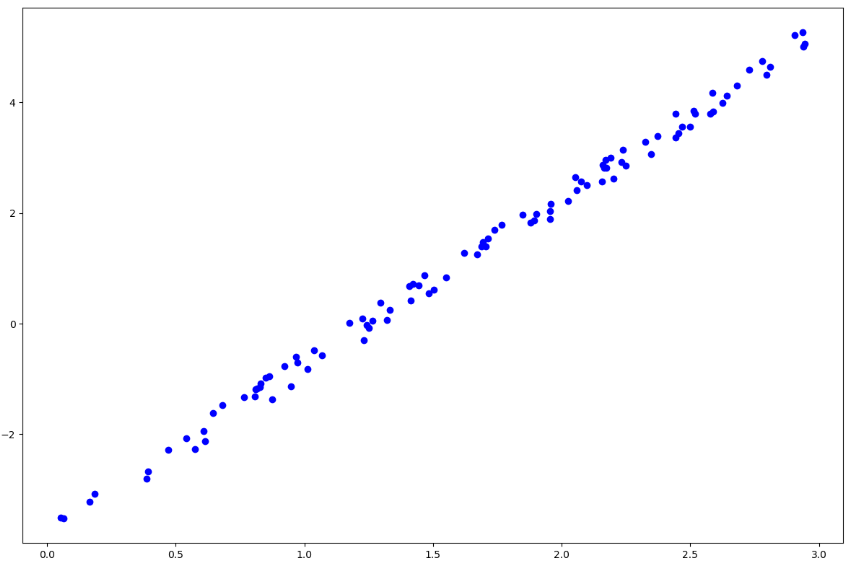
![\[y = 3x - 4 + noise \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-fc1e38319edca88e658b2097a1afbdb3_l3.png "Rendered by QuickLaTeX.com")
で二つ作りました。見ての通り上の方がノイズが大きいです。今回の予測モデルは直線
![\[y=mx+b\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-b2cf14624e392933909f61673351ab22_l3.png "Rendered by QuickLaTeX.com")
とします。サクッとPYTHONで書くと下のような結果がとれます。まずノイズが小さい方のデータに対して
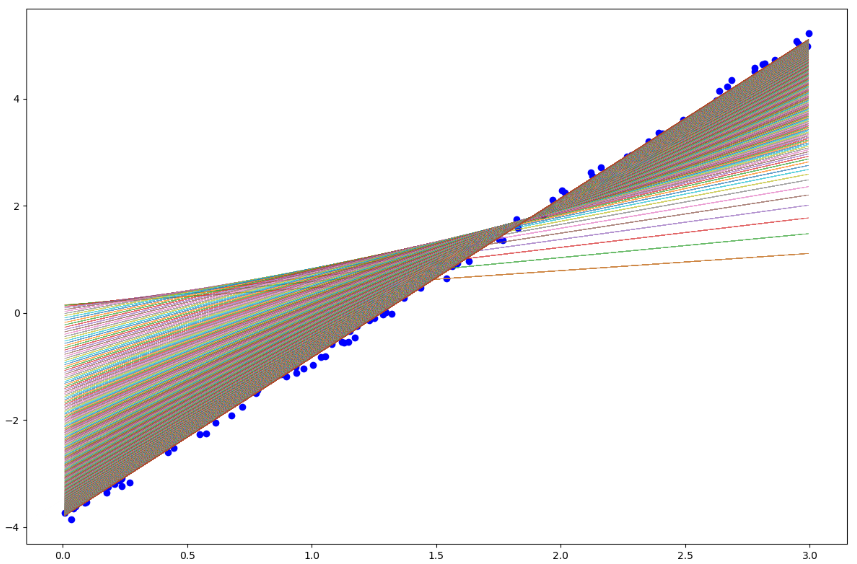
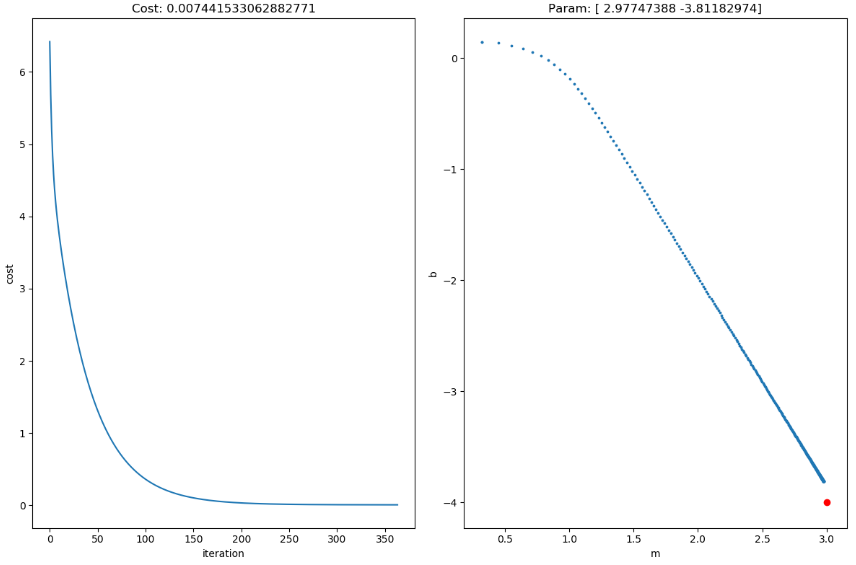
コストが減っており、それに合わせてパラメータ も本来の
も本来の に収束しようとしています。上のプロットが見にくいのですが、学習の際のパラメータ履歴で直線をプロットしたものです。次にノイズが大きい方の結果を見てみましょう。
に収束しようとしています。上のプロットが見にくいのですが、学習の際のパラメータ履歴で直線をプロットしたものです。次にノイズが大きい方の結果を見てみましょう。
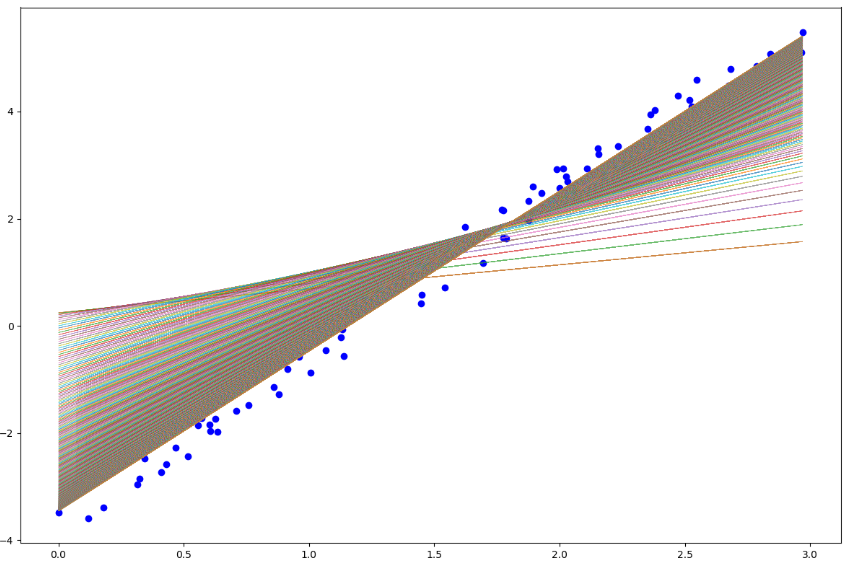
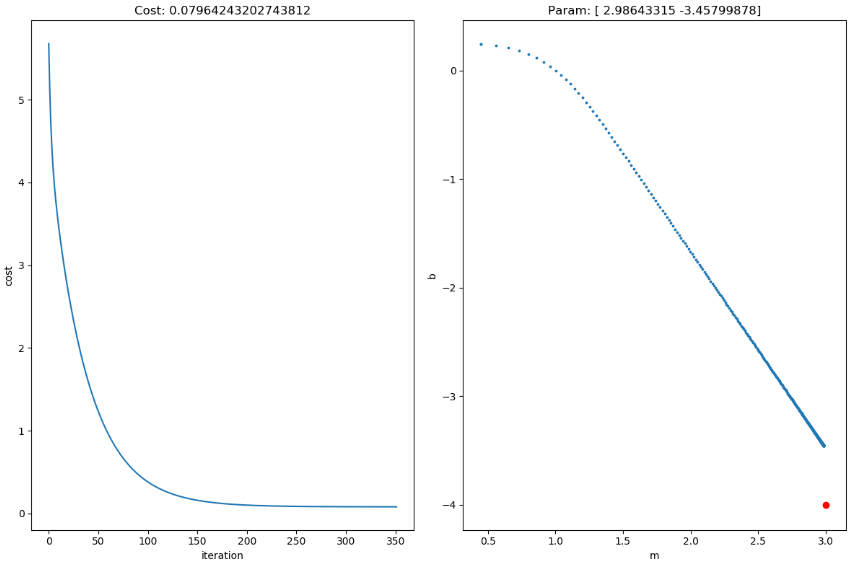
同様にコストも減り、パラメータも本来の値に近ずいてはいますがどおも届きそうにないです。iteration=150あたりで学習が止まっているのでこれ以上は赤点に近づかないでしょう。これはノイズが大きいことが原因です。
とりあえず線形回帰を二変数で行いましたが多変数になってもやり方は全く変わりません。コードを書くのが面倒になりますが sklearnにはすでにlinear regression含め他にも多くの手法があるので簡単に回帰ができます。詳しくは「python 線形回帰 sklearn」などでググればいっぱい出てくるので見てください。
ところで
線形回帰をいい例題にして行列の勉強を簡単にしましょう。というのは何かというと、実は、勾配法使わなくても一発で解が出るんです。
![\[ y_i = 1 * \beta_0 + x_{i1} * \beta_1 + x_{i2} * \beta_2 + \cdots + x_{ik} * \beta_k + \epsilon_i \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-ec022e6a43d93d090f1ebee3b7efecc3_l3.png "Rendered by QuickLaTeX.com")
というモデルを考えます。これを行列表記すると
![\[\begin{bmatrix} y_1 \ y_2 \ \vdots \ y_n \ \end{bmatrix} = \begin{bmatrix} 1 & x_{11} & x_{12} & \cdots & x_{1k} \ 1 & x_{21} & x_{22} & \cdots & x_{2k} \ \vdots & \vdots & \vdots & \vdots & \vdots \ 1 & x_{n1} & x_{n2} & \cdots & x_{nk} \ \end{bmatrix} \begin{bmatrix} \beta_0 \ \beta_2 \ \vdots \ \beta_k \ \end{bmatrix} + \begin{bmatrix} \epsilon_1 \ \epsilon_2 \ \vdots \ \epsilon_n \ \end{bmatrix}\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-2e1bd8f0c8a67d3a1560eb978fe8ff5b_l3.png "Rendered by QuickLaTeX.com")
![\[y = X \beta + \epsilon \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-8c876d8170eb55dc937c1b228d9f6b34_l3.png "Rendered by QuickLaTeX.com")
ただし、 はデータ数、
はデータ数、 は次元(変数の数)とした。ここで前回の理論編を思い出すと今回の最適化は誤差二乗和の最小化であった。よってノルムの定義を思い出せば
は次元(変数の数)とした。ここで前回の理論編を思い出すと今回の最適化は誤差二乗和の最小化であった。よってノルムの定義を思い出せば
![\[\frac{1}{2} | \epsilon |^2 = \frac{1}{2} | y - X \beta |^2 \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-1b86215c22ad1ef26987ae60cf9dd09b_l3.png "Rendered by QuickLaTeX.com")
を最小化すればいい(1/2は計算上の都合、別になくても良い)、これを計算する。ベクトルの微分については
- https://www.ics.uci.edu/~welling/teaching/KernelsICS273B/MatrixCookBook.pdf
- https://atmos.washington.edu/~dennis/MatrixCalculus.pdf
ここあたりがいい教材だと思う。もちろん「ベクトル 微分」で検索しても多く出てくる。
今回使うのは次の3つ。
![\[ \frac{\partial }{\partial x} a^Tx = a\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-2f0e686f8e781644ac4d6f90fc2fe6a3_l3.png "Rendered by QuickLaTeX.com")
![\[ \frac{\partial }{\partial x} x^Ta = a\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-deeb23b4481cec07483864cd19fc9b9e_l3.png "Rendered by QuickLaTeX.com")
![\[ \frac{\partial }{\partial x} x^TAx = (A + A^T)x\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-393a226a88ad9d293d05d117b20e700f_l3.png "Rendered by QuickLaTeX.com")
では計算すると
![\[\frac{1}{2} | y - X \beta |^2 = \frac{1}{2} (y - X \beta)^T (y - X \beta) \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-72e6d76793407f6dba2c421643891333_l3.png "Rendered by QuickLaTeX.com")
![\[\frac{1}{2} | y - X \beta |^2 = \frac{1}{2} ( \beta^TX^TX \beta - 2y^TX\beta +y^Ty ) \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-dbc6b4048bccccfb84b813e1b4e7236c_l3.png "Rendered by QuickLaTeX.com")
![\[\nabla_\beta \frac{1}{2} | y - X \beta |^2 = (X^T X + (X^T X)^T)\beta - 2X^Ty \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-8b08d9613ef0a7cb6f1279e248e981eb_l3.png "Rendered by QuickLaTeX.com")
これを0と置くと
![\[ X^T X \beta = X^Ty \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-172442a01580f2acc926c05bff24b5d5_l3.png "Rendered by QuickLaTeX.com")
ここで
 が正則行列を仮定すると
が正則行列を仮定すると
(機械学習の観点から「正則行列」を説明すると「どの列もほとんど似通ってない」になる)
![\[\beta = (X^T X)^{-1} X^Ty \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-76dff7a304f279643293330173587e65_l3.png "Rendered by QuickLaTeX.com")
と求まる。これが最も誤差が最小であるときのパラメータである。
なんの射影?どこへの射影?
そう、この疑問は大切だ。今私たちが扱っているのは である。
である。 についてじーっと見るとこれは
についてじーっと見るとこれは の各列ベクトルの線型結合(四則演算)となることがわかる。たとえば
の各列ベクトルの線型結合(四則演算)となることがわかる。たとえば![X = [X_1 X_2 \cdots X_n]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-f9713d1ace5029e154efde5027a369ec_l3.png "Rendered by QuickLaTeX.com") と表し、
と表し、![\beta=[ \beta_1 \beta_2 \cdots \beta_n ]^T](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-5e4cab456f57cfc0b00fca059cb34bc5_l3.png "Rendered by QuickLaTeX.com") とすると
とすると
![\[X \beta = X_1 \beta_1 + X_2 \beta_2 + \cdots X_n \beta_n + \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-0686e9860b1245ebf783525bc34f41be_l3.png "Rendered by QuickLaTeX.com")
となることがわかる。ここで各 はベクトルであり
はベクトルであり はスカラーであることに注意する。したがっての各列ベクトルの線型結合で出来上がったベクトルの中でもっとも
はスカラーであることに注意する。したがっての各列ベクトルの線型結合で出来上がったベクトルの中でもっとも に近いやつ(似ているやつ)が
に近いやつ(似ているやつ)が
![\[X\beta = X(X^T X)^{-1} X^Ty \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-9add6f71881b72d471eb73bf924a62bd_l3.png "Rendered by QuickLaTeX.com")
となるのだ。ここで
![\[X(X^T X)^{-1} X^T \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-77819da1ae91ffae48a96a11df999240_l3.png "Rendered by QuickLaTeX.com")
を
の列ベクトルが張る空間への射影行列
と呼ぶ。「射影」という考え方は機械学習において非常に重要なので、ぜひ覚えておきましょう。