こんにちは。
今回はマーケティング分野で有名な傾向スコアについてやっていきます。ちなみにですけど巷では次の本が流行っているらしいです。
- https://www.amazon.co.jp/効果検証入門〜正しい比較のための因果推論-計量経済学の基礎-安井-翔太/dp/4297111179
- https://qiita.com/nekoumei/items/648726e89d05cba6f432
まず初めにですが、傾向スコア分析とアップリフトモデリングは別の手法です。当初僕はごっちゃになっていました。まあ後者はこの記事では触れませんが、、
とりあえずこの記事のフォーカスは「因果」です。因果を図ります。まずは簡単に用語の説明から。
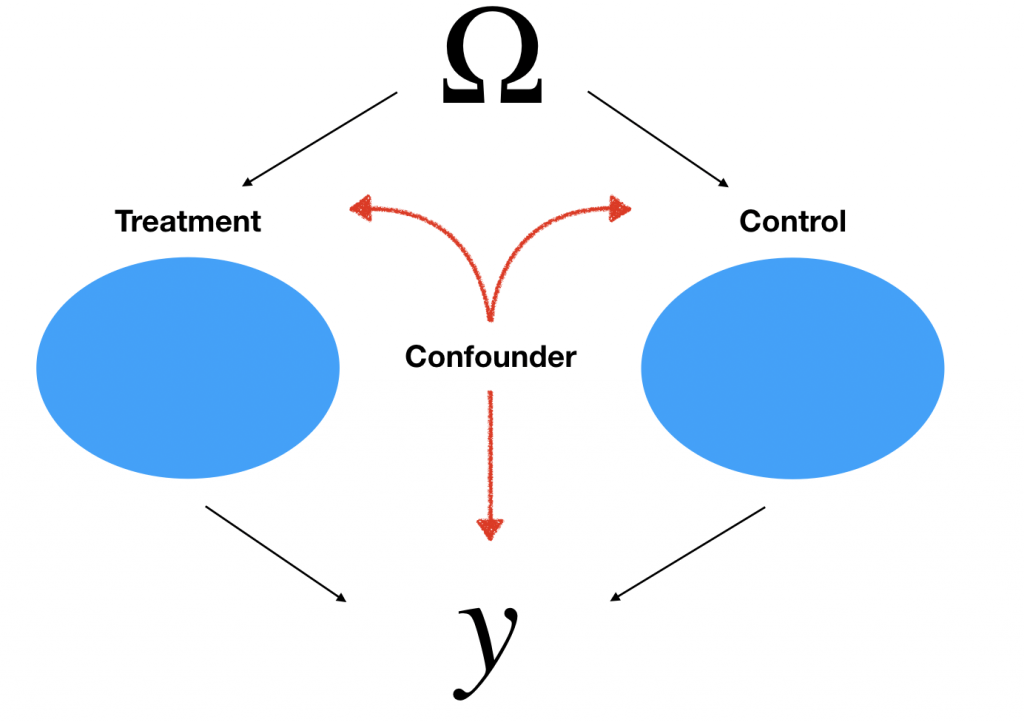
今からする話は上の構造を元に成り立っています。例えばサイゼリアのクーポンの例を用いて解説します。
- Treatment is クーポンを貰った人たちの集合
- Control is 貰ってない人たちの集合
- Confounder is 年収、外食の頻度など(交絡因子/共変量)
 is 全データの集合
is 全データの集合 is サイゼリアに行ったかどうか(購入額もおk)
is サイゼリアに行ったかどうか(購入額もおk)- Selection Bias is トリートメントとコントロール集合間の分布のズレ(共変量シフト的なイメージ)
たとえばこのクーポンの効果を図りたいとします。この時TreatmentとControl間で差を見るだけでは正確ではないかもしれません。その原因がConfounderによるSelection biasです。つまり、集合間で分布に差が生じてしまうかもしれないからです。
実際今回の例で用いるデータを単なる集合間の引き算で算出するとその値は真の値(設定したもの)と異なりました。なのでもっといい因果効果の測定方法についてみていきましょう。
Rubin Model
因果推論で有名なのはこの人、Rubinさんです。因果効果の最もベーシックな考え方は次の画像です。
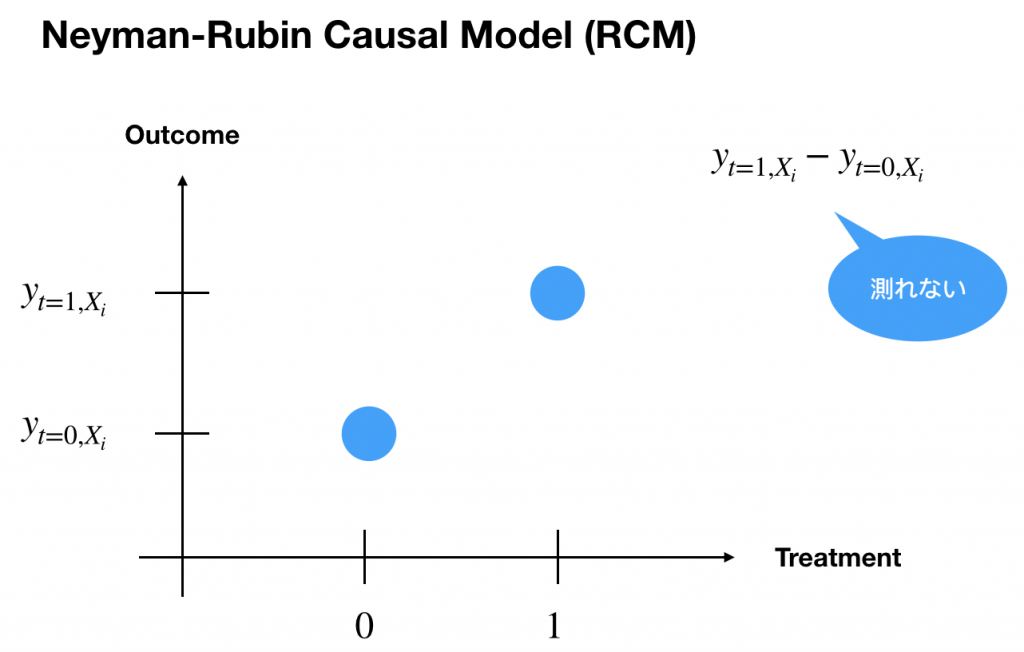
図からわかるようにデータを さんで考えた時にTreatmentの効果があるかどうかは物理的に測定できません。なぜなら「仮に〜だったら」のデータは得られないからです。
さんで考えた時にTreatmentの効果があるかどうかは物理的に測定できません。なぜなら「仮に〜だったら」のデータは得られないからです。
先ほどの例も含めて、因果効果を図るのはやはり非常に難題です。
ただ、解決策の一つとしては各集合間に無作為な割り当てを行えばいいかもしれませんが、実はそれは現実的ではありません。なぜなら例えば治療薬を例にとります。患者さんのあらゆる共変量を考慮してTreatmentの割り当てを行うため、どうしてもSelection biasが起きてしまいます。そこで使われる手法が傾向スコアを用いた層別化(これもマッチング)やマッチングです。
SUTVA
Stable Unit-Treatment-Value Assumptionの略です。RubinのモデルにはSUTVAという重要な仮定があります。
The potential outcomes for any unit do not vary with the treatments assigned to other units, and, for each unit, there are no different forms or versions of each treatment level, which lead to different potential outcomes.http://utstat.toronto.edu/~nathan/teaching/STA305/classnotes/week4/sta305week4classnotes.html#stable-unit-treatment-value-assumption-sutva
つまり、任意のOutcomeは他の個体に割り当てられたTreatmentに干渉しない。例を出すと、Aさんがサイゼリアに行った結果、サイゼリアがめちゃめちゃ人気になってしまってみんなクーポンを欲しがるのはダメ。という感じですかね?これを数式で表すと
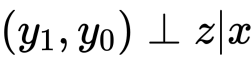
です。つまり共変量( )を固定した場合、Outcome()は割り当て(
)を固定した場合、Outcome()は割り当て( )と独立である。ことが重要な仮定になります。 もう一度具体例で噛み砕きます。
)と独立である。ことが重要な仮定になります。 もう一度具体例で噛み砕きます。
- 共変量(年齢、性別など)のみがクーポンの配布(割り当て)を決定する
- 共変量が等しければ割り当ては同確率
このおかげで先ほどの「仮に〜だったら」のデータを擬似的に得ることができます。つまり、共変量が等しいデータを探すということです。
しかし、先ほどの治療を例にこの仮定を考え直してみます。共変量としてシンプルに年齢を考えます。この時、Treatmentここでは薬Aの割り当ては本当に年齢のみによって決まるでしょうか?また、共変量は現実問題では観測されない可能性も考えると共変量が等しいという状況に疑問が抱かれます。なので「共変量が等しいデータを探し方」について次は探っていきましょう。
Propensity Score
Rubinはまず次の関数をバランシングスコアと定義しました。
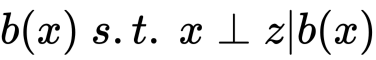
そしてRosenbaumとRubinは傾向スコア を次のように定義しました。
を次のように定義しました。
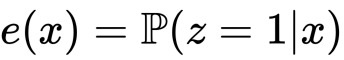
そして彼らはいくつかの定理を証明し、最終的に次の主張を得ました。
- Propensity Score is Balancing Score
- 任意のBalancing ScoreはPropensity Score、if and only if、

- Balancing ScoreはSUTVAを満たす
ここで、 としてidentity functionをとることで
としてidentity functionをとることで が傾向スコアであることがわかります。これらを用いて傾向スコアマッチングや層別解析が誕生しました。SUTVAの仮定を用いると
が傾向スコアであることがわかります。これらを用いて傾向スコアマッチングや層別解析が誕生しました。SUTVAの仮定を用いると
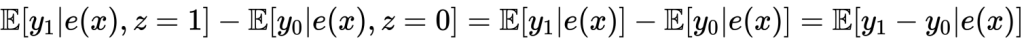
また、
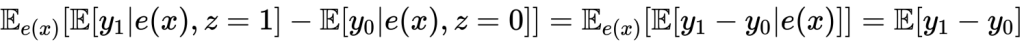
が得られます。なお、傾向スコアについてはロジスティックモデルが一般的のようですが、決定木などでもいいです。
ということで「共変量が等しいデータを探し方」についてですが、「傾向スコアが等しいデータ」で代用できることがわかりました。あとは分析手法を見て実装するのみです。
層別解析
傾向スコア分析はいくつか手法があります。ここではまず層別解析についてです。これは単純で、傾向スコアをブロック分割します。
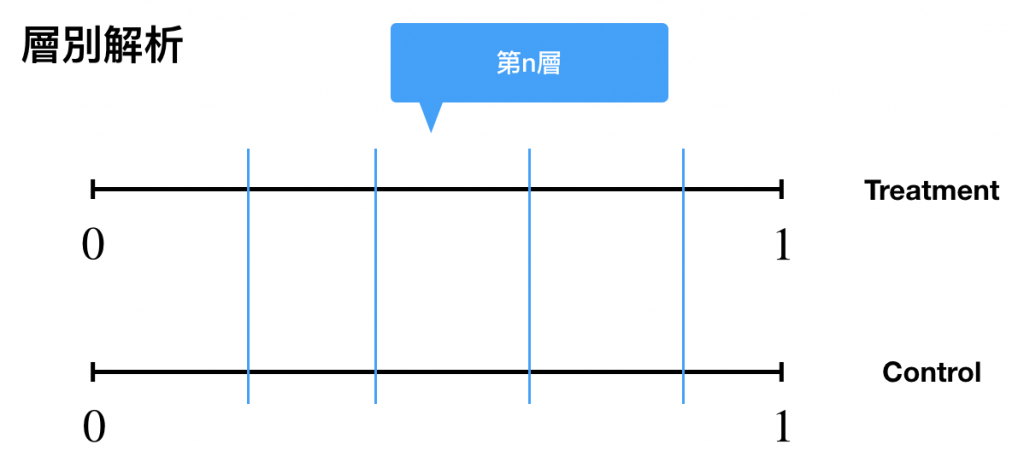
傾向スコアにはロジスティックなどを持ちいると仮定するので、![e(x) \in [0,1]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-ae941a50825536228f728ea852209bd4_l3.png "Rendered by QuickLaTeX.com") になります。
になります。
層別に分けてそれぞれの層においてOutcomeの平均の差で因果効果を算出します。ここで についてですが通常はサブクラスのサイズが等しくなるように分割するらしいです。個人的にはを細分化すればするほど精度があがるんじゃないかなと思っています。
についてですが通常はサブクラスのサイズが等しくなるように分割するらしいです。個人的にはを細分化すればするほど精度があがるんじゃないかなと思っています。
Matching
2つ目の手法はマッチングです。といっても層別も層別マッチングなんですけど、、、、まあ置いておいて、、TreatmentとControlの各集合の要素をPropensity Scoreの類似度でマッチングします。この時、最近傍やマハラノビス距離を用いた手法などいろいろありますが、ここではキャリパーマッチングを実装します。これはマッチングに閾値を設ける手法です。
下の図のようなマッチングが得られたとします。
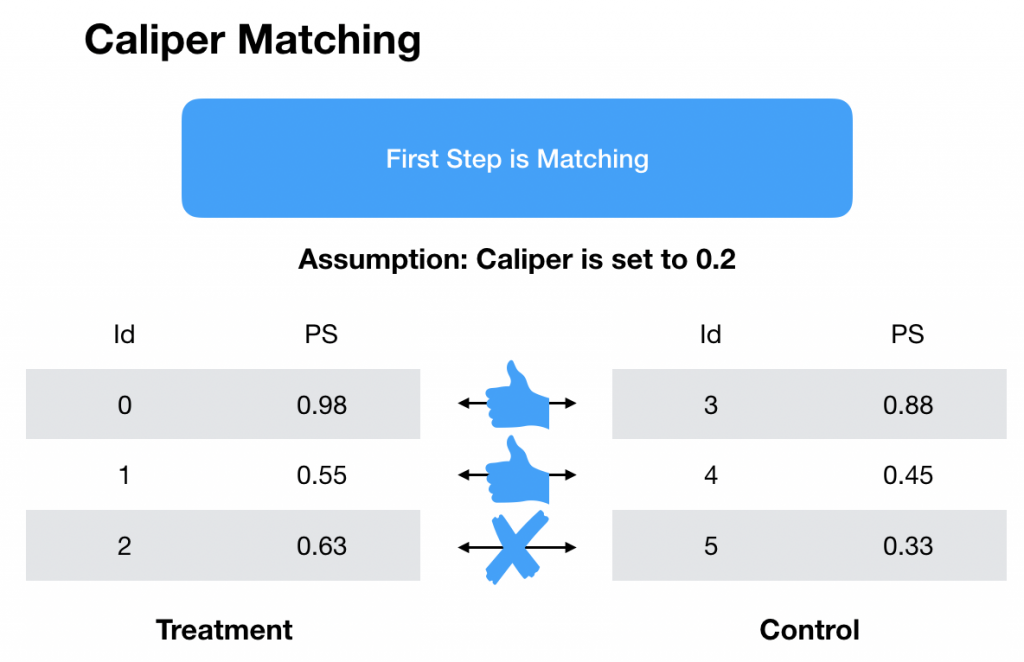
キャリパーマッチングでは三つ目のマッチングにおいて傾向スコアの差がCaliperを超えている( )のでマッチング不成立となります。成立したデータを対象に層別の時と同様に平均の差で因果効果を算出します。
)のでマッチング不成立となります。成立したデータを対象に層別の時と同様に平均の差で因果効果を算出します。
とはいえ実はマッチングはSUTVAの仮定などが原因で良くないらしいです。
傾向スコアマッチングが近似しようとしているのは完全なランダム化である.これは共変量を1次元の指標にして,共変量とは独立にトリートメントの効果を推定しようとしていることからも明らかである(本文中に書かれているが1対1マッチングにおいて同じ傾向スコアのマッチング相手がいたらランダムにどちらかを選ぶ).それに対して,マハラノビス距離やCEMなど他の方法は完全にブロック(層化)したうえでのランダム化に近似しようとしている(各共変量の距離を計算するので).したがって,傾向スコアマッチングよりもマハラノビス距離マッチングやCEMの方が望ましいということである.というわけで,Kingらはマッチングをする際にはマハラノビス距離やCEMを利用することを薦めている.ただし,傾向スコアが数式的に問題があるというわけでなく,またマッチング以外に傾向スコアを用いることについては今回の指摘はあてはまらないと繰り返している. http://analyticalsociology.hatenadiary.com/entry/2017/09/11/121102
そこで登場するIPWという手法も見てみたいと思います。
IPW
冒頭でも申したとおり、単純に集合間で引き算をするとやはり共変量シフトによる選択バイアスが大きく現れます。そこでこのバイアスの修正を試みる手法がIPWになります。
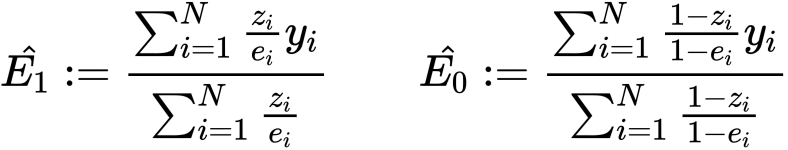
具体的には上のようにすることでバイアスを修正しつつ、ルービンの難題であった『〜だったら』の時の不偏推定量となることが次のリンクよりわかります。
まだいろいろありますが、内容が難しく、理解できてないのでいったんここで切ります。
実装
使うデータはこんな感じです。リンク先のデータを使わせていただきました。そこではIPWのみの実装になっていたので今回紹介した、層別とキャリパーで比較してみようと思います。

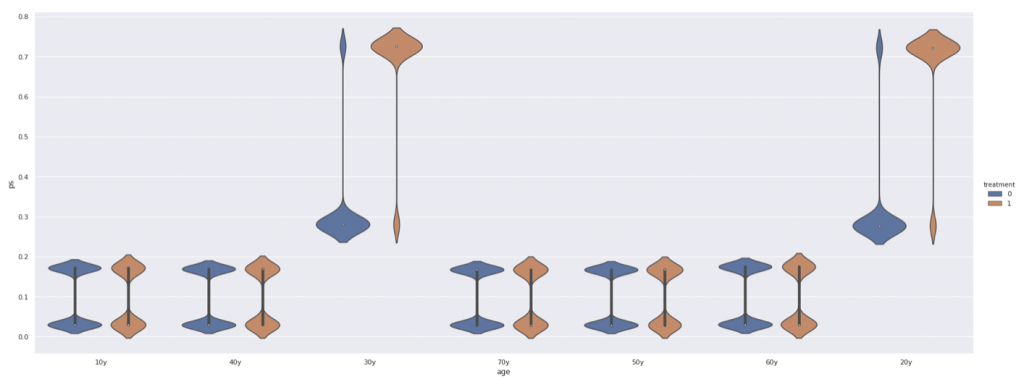
20代、30代の男性にバイアスを載せました。詳しくはコードを見て下さい。結果としてはIPWが最もいい精度でした。
アップリフトモデリングやります。でわ
References
- http://www.stat.cmu.edu/~ryantibs/journalclub/propensity.pdf
- https://qiita.com/nekoumei/items/648726e89d05cba6f432
- https://www.slideshare.net/takehikoihayashi/propensity-score-analysis-seminar-japanese
- https://www.slideshare.net/okumurayasuyuki/ss-43780294
- http://rcommanderdeigakutoukeikaiseki.com/propensity_score.html
- https://blog.datarobot.com/jp/causality_analysis_machine_learning2
- https://pira-nino.hatenablog.com/entry/casual_inference
- https://qiita.com/deaikei/items/df3626486986566cb65c