こんにちは。
本日は強化学習に入門します。けどMDPとかはやらないので安心してください。簡単だと思います。ビジネスにおいてもバンディット問題は多くあるということなのでためになるかなーと思います。
Keywords
この記事のキーワードを先にリストアップします。こうしたほうが読みやすくないか?と最近やっと気づきましたすいません。
- Exploitation / Exploration
- MAB (Multi-Armed-Bandit)
- Advertising Technology
- A/B Test
- Bayesian A/B Test
 – Greedy
– Greedy- Boltzmann Softmax
Exploration / Exploitation
- Exploitation is 活用
- Exploration is 探索
になります。僕の日常生活を例にして説明します。
ラーメンが好きで毎回行きつけのラーメン屋さんにいくんですよね。もちろん、毎回いっているということはそこが美味しいって経験からわかっているので通っているんです。これがExploitationです。
しかし、同じラーメン屋さんにばかり通っていると仮に近くにもっと美味しいラーメン屋さんやつけ麺屋さんがあってもその存在を知り得ないですよね。なのでたまには自分の知らないお店に期待していきたくなりますよね。僕も3回に1回くらいの割合で新しいお店を体験します。これがExplorationです。
ただ、新しいお店だと「美味しい!」時と「普通かなー」な時と「んー」な時がありますよね。これらを報酬といいます。もちろん報酬の高い、つまり「美味しい!」を選択できるようなExplorationができれば理想ですね。
これらを考慮すると、ベストな選択としては行きつけでExploitationしつつも期待度の高いお店にExplorationしたいですよね。
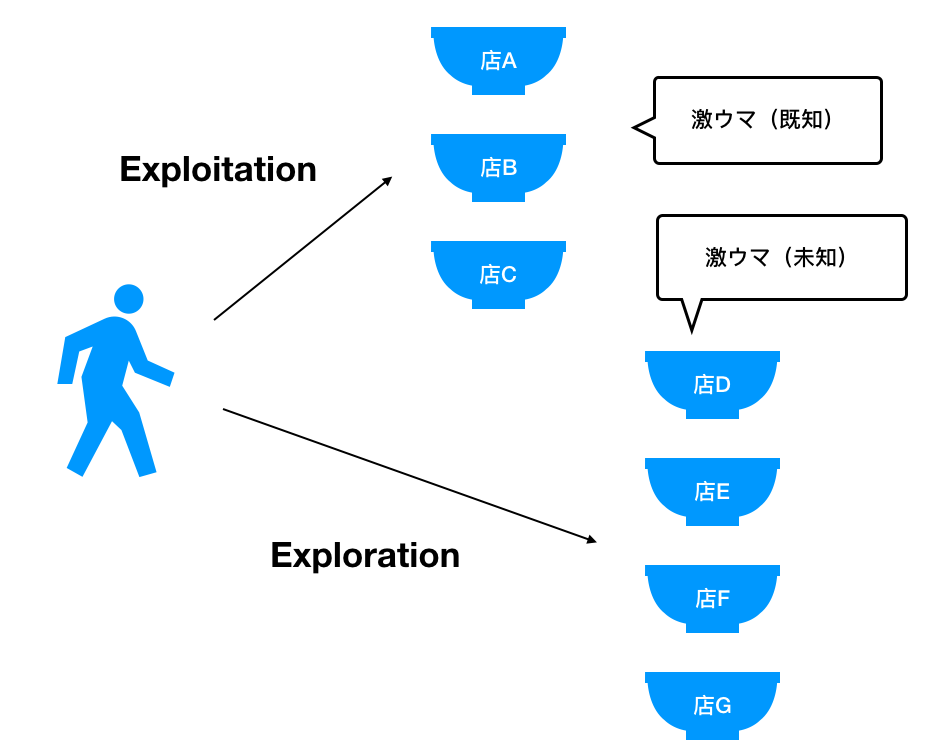
期間 内で探索・活用をベストな比率で行って最終的に最高の報酬(満足度)を得たい!がBandit問題です。
内で探索・活用をベストな比率で行って最終的に最高の報酬(満足度)を得たい!がBandit問題です。
Multi-Armed Bandit
上記のように複数の選択肢に対してExploration / Exploitationを考える問題を多腕バンディット問題といいます。
- 期待値がわからないK個の選択肢が存在する
 回の試行全てにおいて最善の選択肢を選び続けトータルの報酬を最大化したい
回の試行全てにおいて最善の選択肢を選び続けトータルの報酬を最大化したい
という感じです。(お気づきの方もいるかもしれませんが状態 を考えません。厳密には
を考えません。厳密には )
)
もっともポピュラーな例は広告の最適化とかですかね。薬の投与などもたまにExampleで見られますがここでは広告を例にして話を進めます。なのでいったんBanditからは離れてこれについてちょっと深入りしていきます。
Advertising Technology
広告に関わる全住民つまり、広告主側と媒体側(広告主,メディア,消費者)を幸せにするためのテクノロジーです。
そのなかでもReal time bidding(RTB)がキーワードになります。それを説明する前に次の用語を簡単に
- DSP (Demand-Side Platform)
- SSP (Supply Side Platform)
DSPは広告主側の広告効果を最適化するため、ユーザーに適した単価の安い配信先を探す側。媒体側の広告収益を最適化するため、より高額な広告に入札する側です。
つまり、DSPが「この広告貼ってー」とお願いし、SSPが「ええよー」と返します。しかし、一対一関係ではないので「俺の広告も貼ってくれー」といろんな人がお願いします。(SSPも複数あります。サイトA、サイトB的な感じです)
そんなマーケットのことをRTBといいます。複数のDSPが各々資金を持ってSSPに交渉し、最も価格の高いDSPをSSPが決定します。ただ値段の妥当性がわからないですよね。これも機械学習で最適化するそうです。そこで次の用語が登場します。
- CVR:ConVersion Rate.コンバージョン率
- CTR:Click Through Rate.クリック率
これらの指標をもちいてDSPの値段が決定されたりします。これ以上はここでは触れません。気になる方は参考文献より飛んでください。
Bayesian A/B Test
A/Bテストってご存知ですよね。AとBどっちがいいの??を統計学的仮説検定を元に検証する試験のことです。
Bayesian A/Bテストとは、A/Bテストをベイズでやろう!!のことです。たとえば商品Aの購入率が 、商品Bの購入率が
、商品Bの購入率が としたとき分布に有意差あんの?をベイズで解決します。
としたとき分布に有意差あんの?をベイズで解決します。
この方の記事が最高に纏まっています。一応僕もベイズ推定の記事書いてます。
ちなみにバンディットのアルゴリズム実装の最後にベイズ使うので理解しておくことをおすすめします。
Banditを再確認
これらを踏まえてBanditをおさらいすると
バンディットアルゴリズムはアームを選択した結果得られる報酬を逐次的に反映し、次のアームの選択に活かすことからA/Bテストに比べて機会損失の低減が見込めます。いわば逐次最適化A/Bテスト的な感じですかね。
加えてですねえ、A/Bテストは事前分布の問題もあるのでねえ、では次のセクションで最適化に移るためにBandit Algorithmを定式化します。

英語やああああああ、と思わないでください。よく見てくださいめっちゃ簡単な単語しか出てきてません。
注目して欲しいのは です。これは行動
です。これは行動 を入力とする行動価値関数と言われます。
を入力とする行動価値関数と言われます。

注目すべきはRegret(後悔)です。これは最適な行動価値から実際にとった行動価値の差分で定義されます。定義より小さいほうがいいことがわかります。
– Greedy
では一つ目のアルゴリズムの紹介です。
- パラメータ
 を設定
を設定 - の確率でExploration
- ランダムでArmを選択
 の確率でExploitation
の確率でExploitation
- 経験を元に、最大の行動価値を持つArmを選択
経験を元に算出される行動価値は次で定義されます
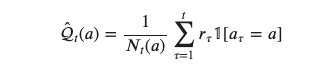
ただし
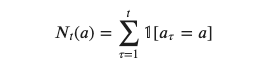
はaction=が選択された総数です。したがってExploitationは次のように定式化されます
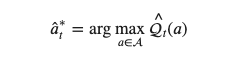
を変化させて実装結果を確認します。アームは10種類でそれぞれの確率は単調増加で設定しました。なのでインデックスでは9番が最大の行動価値をもったアームということになります。


たしかに、を増やすとExplorationが多くされていることがわかりまうす。Rewardsと最適なアームを選んだ割合(BAR)の変化を比較します。

青が小さいでオレンジが大きいでの結果です。をおきくするほど探索の割合が大きくなるのでその影響がBARに顕著に現れています。
Boltzmann Softmax
の問題は探索をランダムで行っている点です。つまり、実際には行動価値の高いアームも低いアームも等確率で扱っていた点です。BoltzmannのアルゴリズムではSoftmax関数を用いることで各アームを経験行動価値で重み付します。その出力をそれぞれのアームの確率で扱います。
- パラメータを設定 (small)
- パラメータ
 を設定 (small)
を設定 (small) - の確率でExploration
- 各Armの行動価値をSoftmaxで重み付けし選択
- の確率でExploitation
- 経験を元に、最大の行動価値を持つArmを選択
定式化すると次のようになります。
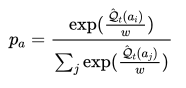
よく見てみると で割り算されていることがわかります。これもハイパーパラメータです。察しの通りで
で割り算されていることがわかります。これもハイパーパラメータです。察しの通りで のとき
のとき となるので-Greedyと同じようになります。
となるので-Greedyと同じようになります。
したがってExploitationは次のように定式化されます
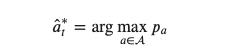
では実装結果を確認します。

-Greedyと比較してみます。
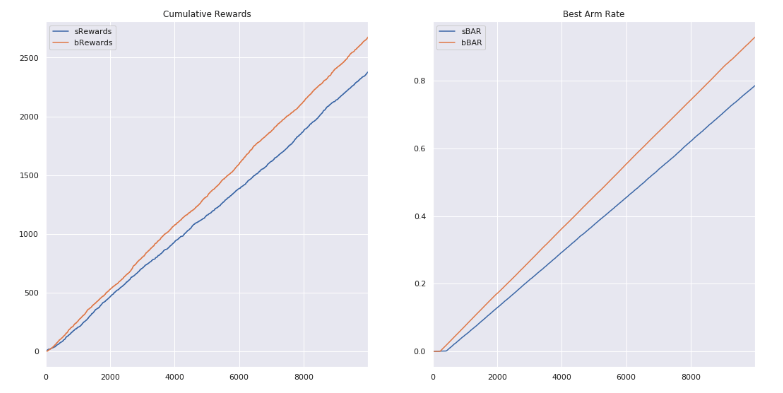
いいかんじ
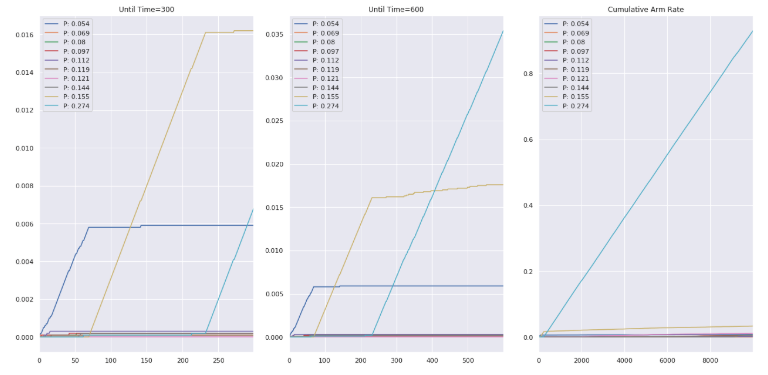
を分割して確認しますとうすい水色である本来のベストなアームが を超えたあたりから盛り返してきてることがわかります。
を超えたあたりから盛り返してきてることがわかります。
最後にコードを貼っておきます。
次回はUDBとThompson sampling実装しますー。でそのノリでContextual Banditとかも頑張りますー。
References
- https://accel-brain.com/semantics-of-natural-language-processing-driven-by-bayesian-information-search-by-deep-reinforcement-learning/verstarkungslernalgorithmus-als-funktionale-erweiterung-des-banditenalgorithmus/
- https://ferret-plus.com/11986
- https://www.cs.princeton.edu/courses/archive/fall16/cos402/lectures/402-lec22.pdf
- https://lilianweng.github.io/lil-log/2018/01/23/the-multi-armed-bandit-problem-and-its-solutions.html
- https://www.smartbowwow.com/2018/08/python.html
- https://haltaro.github.io/2017/08/08/introduction-to-ad-tech
- https://github.com/brianfarris/RLtalk/blob/master/RLtalk.ipynb
- https://blog.albert2005.co.jp/2017/01/23/%E3%83%90%E3%83%B3%E3%83%87%E3%82%A3%E3%83%83%E3%83%88%E3%82%A2%E3%83%AB%E3%82%B4%E3%83%AA%E3%82%BA%E3%83%A0%E3%80%80%E5%9F%BA%E6%9C%AC%E7%B7%A8/
- https://www.cs.princeton.edu/courses/archive/fall16/cos402/lectures/402-lec22.pdf