こんにちは。
皆さんご存知の線形回帰ありますよね。で、あれの発展で一般化線形回帰を昔おこないました。
初耳の方は次の動画が非常に参考になります。
で、一般化線形回帰ってなんなのか?を簡単に思い出すと、回帰したいデータ が正規分布に従わないときに使う応用の回帰モデルなんです。実際、現実世界で得るデータが正規分布以外に従うことなんて多々ありますよね?動画では種子のデータが具体例であげられていました。まあ要は曲がった回帰がしたいんです。
が正規分布に従わないときに使う応用の回帰モデルなんです。実際、現実世界で得るデータが正規分布以外に従うことなんて多々ありますよね?動画では種子のデータが具体例であげられていました。まあ要は曲がった回帰がしたいんです。
で、今回のタイトルにあるポアソン分布と二項分布なんですけど。なぜこれらがテーマかというと正規分布以外に従うデータの分布について復習したいと思ったからです。つまり、ポアソン分布に従うデータってどんなの?二項分布に従うデータってどんなの?という疑問について纏めます。加えて、この二つの分布にはとある関係がありまして、それについても話そうと思います。
Poisson分布
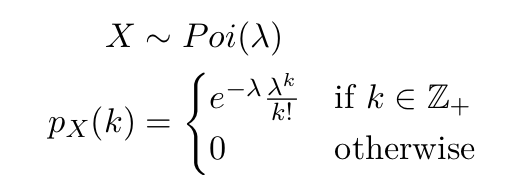
単位時間あたりのとあるイベンドの割合を定数 とします。このとき、そのイベントが単位時間あたりに起こる回数
とします。このとき、そのイベントが単位時間あたりに起こる回数 が従う確率分布です。
が従う確率分布です。
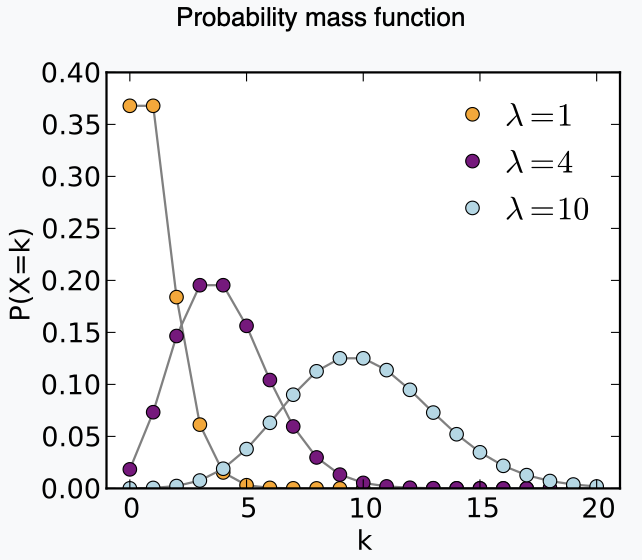
図からわかるように あたりで確率が多きくなっています。個人的に特徴としては離散であることと非負整数であることがあげられます。で、じゃあ例えば実世界ではなにがポアソン分布にしたがうの?という問いに対して箇条書きで例を列挙します。当たり前ですがすべて単位時間あたりに起こる回数です。
あたりで確率が多きくなっています。個人的に特徴としては離散であることと非負整数であることがあげられます。で、じゃあ例えば実世界ではなにがポアソン分布にしたがうの?という問いに対して箇条書きで例を列挙します。当たり前ですがすべて単位時間あたりに起こる回数です。
- 事故が起こる回数
- ウェブサイトがクリックされる回数
- お客さんが来店する回数
- 電話が鳴る回数
- コーディングでタイポする回数
まあ平均 回起こることがわかっているときに
回起こることがわかっているときに 回起きる確率は?みたいなイメージなので例はかなり多いです。ついでに期待値と分散も計算します。
回起きる確率は?みたいなイメージなので例はかなり多いです。ついでに期待値と分散も計算します。
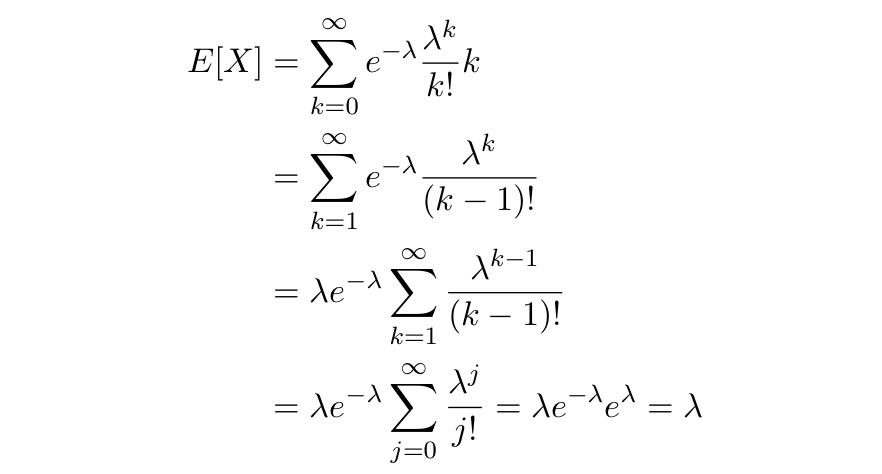
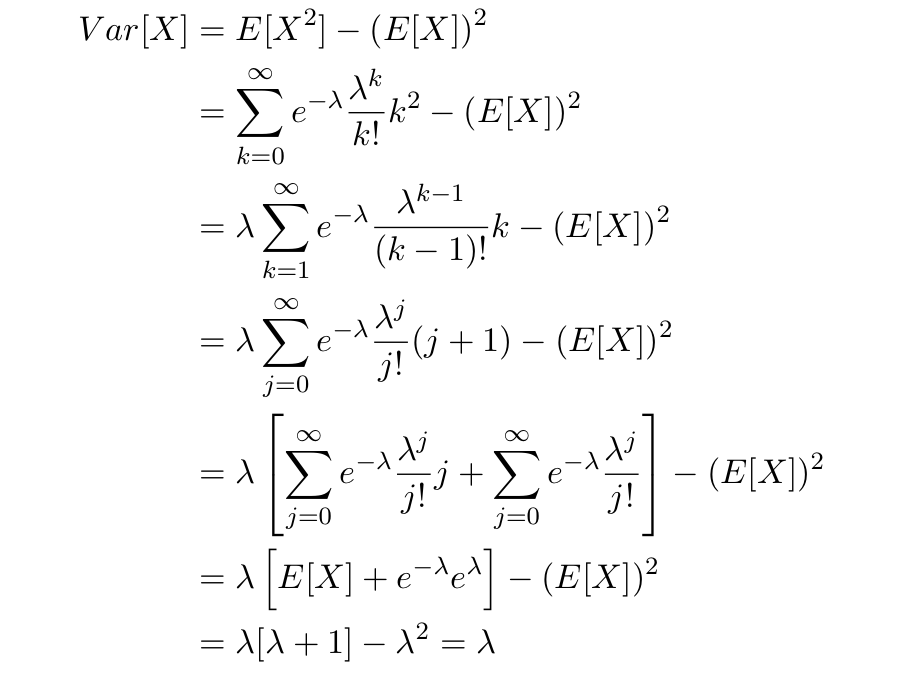
で、逆に考えるとデータの期待値を計算して分散と等しくなればそれはポアソン分布に従うのか?と疑問に思ったんですけどこれって成り立つのでしょうか?コメントお待ちしてます。
Binomial分布
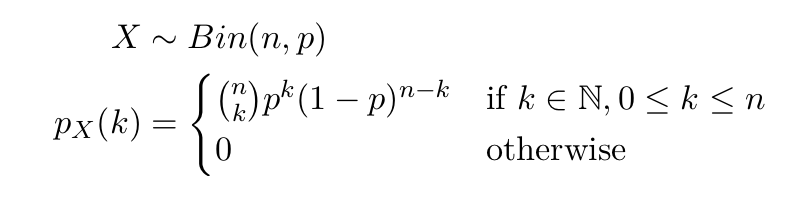
回の独立した試行のうち、成功する回数が従う確率分布です。 は成功する確率です。成功とありますがただのbitだと思ってください。
は成功する確率です。成功とありますがただのbitだと思ってください。
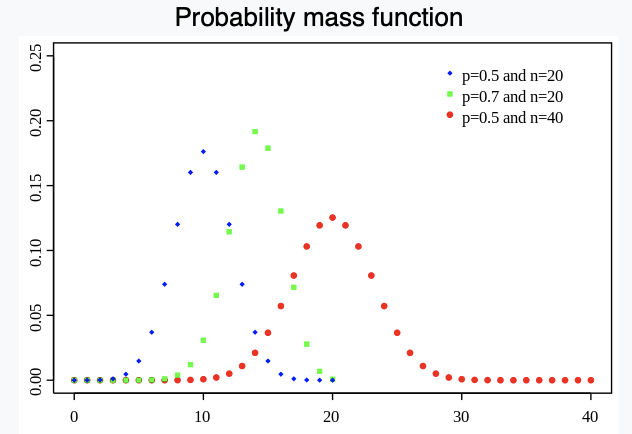
図よりわかるかもしれませんが特に赤色って正規分布に似てませんか?そうなんです実は二項分布は正規分布の近似をすることが可能なんです。そしてこの性質が二項分布の一番の取り柄と言っても過言では無いです。なぜならば信頼区間が計算できるのです。
- De Moivre-Laplace and Poisson Limit Theorems
- Rigorous, real analysis, proof of De Moivre–Laplace theorem
上記のDe Moivre–Laplace theoremが近似を証明する定理です。つまり、二項分布 はが十分に大きい時に平均
はが十分に大きい時に平均 、標準偏差
、標準偏差 の正規分布に近似できます。ここでさらに正規分布を標準化することで
の正規分布に近似できます。ここでさらに正規分布を標準化することで のとき
のとき であることがわかります。これで信頼区間が計算できます。
であることがわかります。これで信頼区間が計算できます。

では先ほど同様実世界の例についてですが省略します。代わりに前述の信頼区間について纏めます。
Binomial Testの例
たとえばコインを30回なげて21回表が出たとします。この時、このコインまさか裏が出やすいのでは?とおそらく皆さん思います。そこでこれはたまたまなのか?それともやはり裏が出やすいのか?どうなのかを検証することにします。そこで、母比率に対して帰無仮説を「フェアなコインである( )」、対立仮説を「フェアなコインでない(
)」、対立仮説を「フェアなコインでない( )」としたいところですが、今回は「裏が出やすい」ということなので片側検定(
)」としたいところですが、今回は「裏が出やすい」ということなので片側検定( )を使います。(
)を使います。( は表の出る確率)
は表の出る確率)
両側と片側の選択は知りたいことによってことなります。たとえばあるプロテインが筋肉増大の効果があるかどうかを調べたければ対立仮説に「母平均 」を使いますよね。なぜなら対立仮説を「」にしてしまうとこのプロテインにはなんらかの効果があるとしか言えないのです。つまり、増大するか減少するかまでスペシフィックに結論づけられないのです。
」を使いますよね。なぜなら対立仮説を「」にしてしまうとこのプロテインにはなんらかの効果があるとしか言えないのです。つまり、増大するか減少するかまでスペシフィックに結論づけられないのです。
気をとりなおして上で話した近似を用いて今回の統計量 を求めます。
を求めます。
![\[T = \frac{21 - 30(1/2) }{ 30(1/2)(1-1/2) } = \frac{ 21 }{ 7.5 } = 2.8\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-2990882dfffedc29a2c6a474acc70614_l3.png "Rendered by QuickLaTeX.com")
で、本当は先に有意水準を決めないとダメらしいんですよね。有意水準とは「このくらいなら起きてもおかしく無い」「この事象が起こるのは珍しすぎるありえない」と判断するための閾値的なものです。
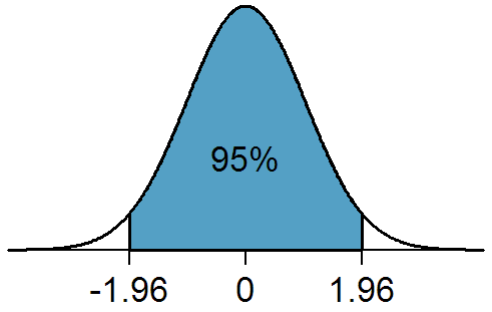
上の図は両側検定における有意水準5パーセントのものです。青い部分が信頼区間を表します。ここで、統計量と信頼区間と有意水準とp値の4点について纏めます。(自分がよく混乱するので)
- 信頼区間
 とは図中の
とは図中の![[-1.96, 1.96]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-1050cff2f8af15df4ab67440c4f7117c_l3.png "Rendered by QuickLaTeX.com") のことです。
のことです。
有意水準を小さくすればするほど広がります。ちなみに有意水準をはじめに決めないといけない理由はこれです。つまり有意水準が信頼区間を決めます。
- 統計量とは図中のx軸上に配置される値です。
この値は起こった事象から計算し、信頼区間に入るか入らないかで帰無仮説が棄却されるかされないかが決まります。
- 有意水準(%)とは「ぎりぎりあり得なくない」と判断するための限界値です。
図中だと を境に青と白の部分が分かれていますがこの白い部分の面積が全体の5%を占めます。なのでたとえば両側検定において有意水準を1%にすると青い部分が大きくなります。
を境に青と白の部分が分かれていますがこの白い部分の面積が全体の5%を占めます。なのでたとえば両側検定において有意水準を1%にすると青い部分が大きくなります。
- p値とは累積確率です。
対立仮説を裏付けるための確率の総和だと思ってください。今回の場合だと表が21回でましたよね。たとえば表が22回だったら対立仮説がますます正しくなりそうですよね?なのでこの場合は表が21〜30回でそれらの確率を総和した値がp値です。(ちなみに計算すると約0.02です)このp値が有意水準を下回っている場合、帰無仮説は棄却されます。
で、話を戻します。今統計量は でした。正規分布表をみて有意水準5%における右片側検定の信頼区間をは
でした。正規分布表をみて有意水準5%における右片側検定の信頼区間をは![I = [-\infty, 1.65]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-df43027ce1a392605be4f3703550b0e5_l3.png "Rendered by QuickLaTeX.com") です。
です。 なので帰無仮説は棄却され、このコインは表が出やすいと結論づけることができました。
なので帰無仮説は棄却され、このコインは表が出やすいと結論づけることができました。
なんだか長くなって統計の記事になりそうなのですがそうではなく、いいたいことを再度確認するとBinomial分布はが十分に大きければ正規分布に近似できるため結果的に統計的検定ができるのです。
こちらもついでなので期待値と分散を計算します。
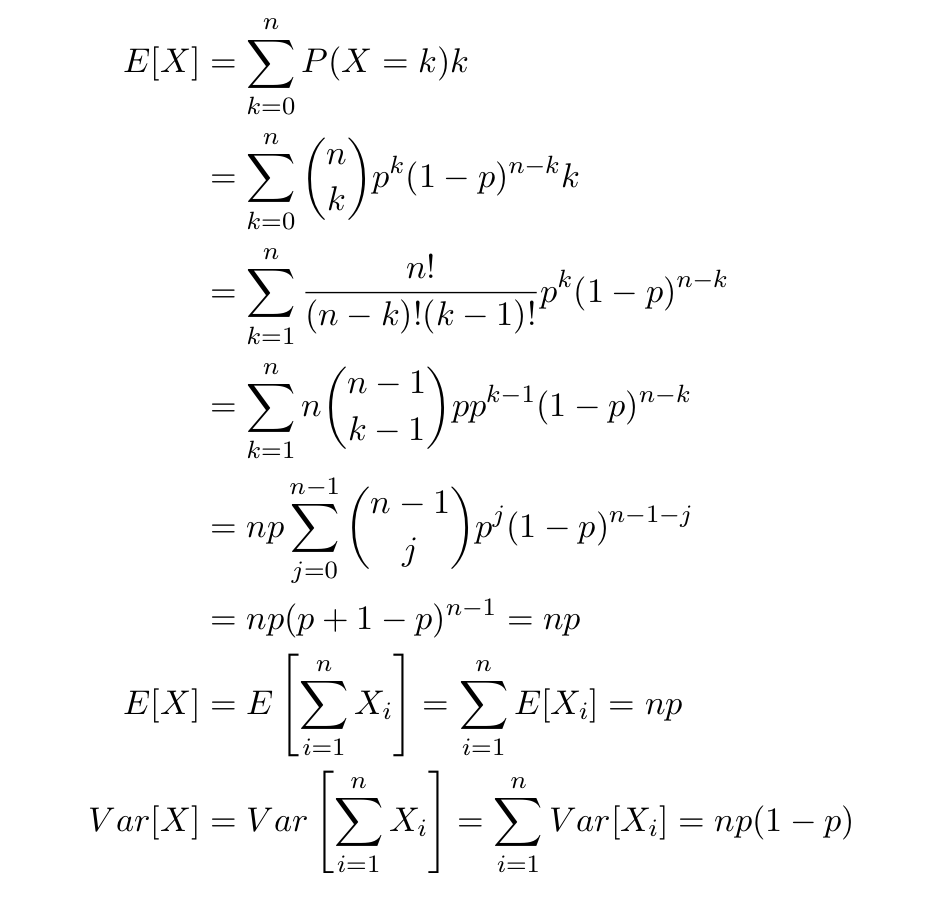
関係
で、個人的にはこれがメインなんですけど。これらの分布には実は関係があるんです。次のような状況を考えます。
試行回数がわからないとします。その代わりに単位時間あたりの成功回数はわかるとします。これをとします。すると になります。これを用いてBinomial分布を書き換えます。
になります。これを用いてBinomial分布を書き換えます。
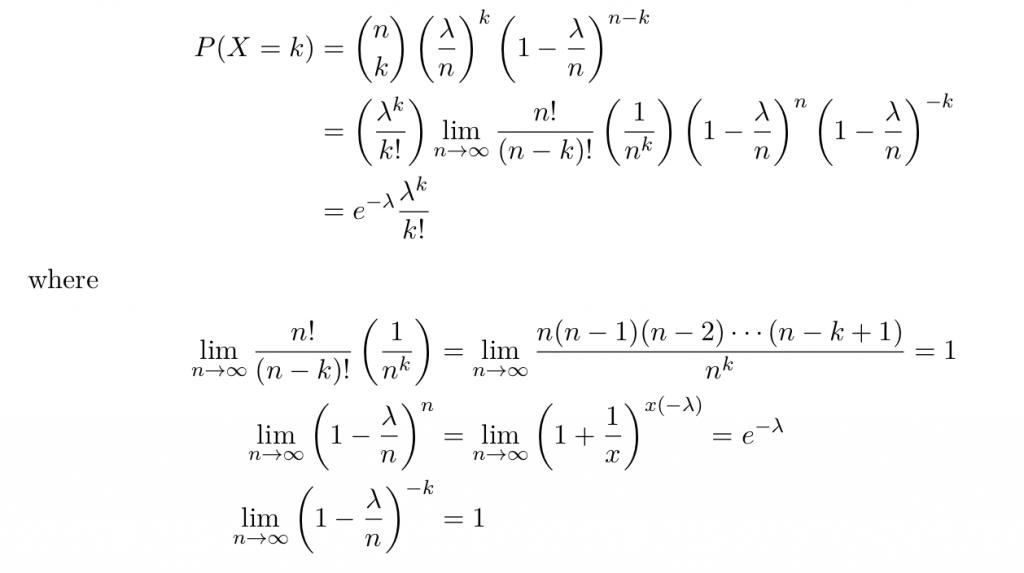
おや、ポアソン分布が登場しました。実は上で申したようにポアソン分布の は定数でないといけないんですよね。そこでが十分に大きくするとを一定に保つにはが十分に小さくなっていかないとだめですよね。すると二項分布はポアソン分布に近似できるのです。
は定数でないといけないんですよね。そこでが十分に大きくするとを一定に保つにはが十分に小さくなっていかないとだめですよね。すると二項分布はポアソン分布に近似できるのです。
え?二項分布って正規分布にもポアソン分布にもどっちでも近似できるの?おかしくないか?と思われたと思います。実は近似に基準がありまして、、、ここからは長くなるので調べてみてください。
ボミューミーな内容になってしまいました、すいません。次回はMCMCです。でわ