こんにちは。
本日は機械学習の基本である尤度からパラメータ推定の基本であるMAP推定について話します。ベイズ推定やMCMCは次回以降になります。
ちなみに、KLや最小二乗法にまつわる話もします。
尤度と確率の違い
これ僕的にはそんなに気にしなくてもいいと思うんですよね、というのは僕が実際わかってないから、笑
- 尤度(Likelihood)
観測した事象が起こる確率(パラメータがある) - 確率(Probability)
直感的な確率(パラメータがない)
例えばコインが二回連続表になる確率は?と聞かれれば
![\[ \frac{1}{2}\frac{1}{2} = \frac{1}{4} \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-af8d131c4268620ffd59fa09d1e123a2_l3.png "Rendered by QuickLaTeX.com")
と勝手に都合よく答えますよね?では尤度は?と聞かれるとまず、表・裏それぞれの確率を定義します。例えば のように。そこでやっと尤度が次のようにかけます。
のように。そこでやっと尤度が次のようにかけます。
![\[ \theta\theta = \theta^2 \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-9dbc5c5b1ba30affd5eaae717836c1df_l3.png "Rendered by QuickLaTeX.com")
尤度関数と最尤法と対数尤度関数
 個のデータを
個のデータを とします。それぞれの確率を
とします。それぞれの確率を とします。ちなみに尤度も尤度関数も同じです。尤度関数を次のように定義します。(観測したデータを下に事象が起こる確率)
とします。ちなみに尤度も尤度関数も同じです。尤度関数を次のように定義します。(観測したデータを下に事象が起こる確率)
![\[L(\theta) = \prod_i p(x_i ; \theta)\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-a5422a75a305753f1484b1a87e25a740_l3.png "Rendered by QuickLaTeX.com")
最尤法は「尤度の最大化」です。またそれは以下の尤度方程式の解として求められます。
![\[ \frac{\partial f}{\partial \theta} \log L(\theta) = 0 \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-4ae662e215bd23361a5747ec25043ea1_l3.png "Rendered by QuickLaTeX.com")
つまり、最尤法の結果得られるものはパラメータの最もらしい確率ということになります。
ちなみに尤度関数に対数をとることがあります。これは計算を簡単にするためです。というのは掛け算が足算になるという利点です。対数をとった対数尤度関数を解くことと尤度関数を解くことが同値であることは対数関数の単調増加性と次からわかります。 の対数
の対数 は微分すると
は微分すると
![\[{\log f(x)}' = \frac{f'(x)}{f(x)} \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-2c953e8e42f21bb10815c6447fe00c5a_l3.png "Rendered by QuickLaTeX.com")
となり のとき
のとき となることがわかります。つまりの極値との極値は一対一に対応するのでこの変換は正当化されます。
となることがわかります。つまりの極値との極値は一対一に対応するのでこの変換は正当化されます。
最尤法の例
あるコイン投げを考え、表が出る確率を とします。
とします。
このコインを 回なげたら
回なげたら 回表が出たという事象を考えます。
回表が出たという事象を考えます。
この事象に対して最尤法により最適なを求めます。
尤度関数は
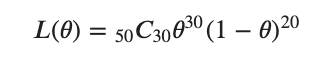
となり、
対数とり(対数尤度関数)
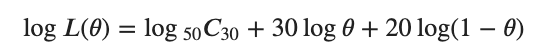
としてから対数尤度方程式を解く
![\[ \frac{\partial f}{\partial \theta}\log L(\theta) = 0\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-9a6c5c43fba13071e1c63a0e15a38739_l3.png "Rendered by QuickLaTeX.com")
![\[ \frac{30}{\theta} - \frac{20}{(1-\theta)} = 0\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-0842d89b4bc7a5895e934c93b9580afe_l3.png "Rendered by QuickLaTeX.com")
以上より ともとまります。
ともとまります。
最尤法と最小二乗法の関係
モデル関数を
![\[ f(x) = \alpha x +\beta\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-85e4612c719f8258727bce997c098c05_l3.png "Rendered by QuickLaTeX.com")
とし、予測値 と実測値
と実測値 の誤差を
の誤差を とします。つまり、
とします。つまり、 が成り立つとします。ここで重要な仮定ですが、誤差はガウス分布に従うものとします。すると仮定より尤度関数は以下のようになります。
が成り立つとします。ここで重要な仮定ですが、誤差はガウス分布に従うものとします。すると仮定より尤度関数は以下のようになります。
![\[L(\theta) = \prod_{i=1}^{n}(2\pi\sigma^2)^{-1/2}\exp{-\frac{(y_i-f_i)^2}{2\sigma^2}}\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-b3eb6ce0b26e41e7b93071b551cb4626_l3.png "Rendered by QuickLaTeX.com")
ここで対数をとり整理すると、以下の対数尤度関数を得ます
![\[\log L(\theta) = -\frac{n}{2}\log(2\pi\sigma^2)-\frac{1}{2\sigma^2}\sum_{i=1}^{n}(y_i-f_i)^2\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-6391c5e83a70f0c68c226d68e9fe0b86_l3.png "Rendered by QuickLaTeX.com")
ここで振り返るとこの関数はが唯一のパラメータなので 内を最小化させるような
内を最小化させるような を見つけることで最尤法が達成されることがわかります。これはまさに最小二乗法と同値であることがわかります。
を見つけることで最尤法が達成されることがわかります。これはまさに最小二乗法と同値であることがわかります。
KLの最小化と尤度最大化の関係
を真の分布、 を私たちのモデルとします。KLを最小化するには以下の第2項を最大化させればいいことがわかります。
を私たちのモデルとします。KLを最小化するには以下の第2項を最大化させればいいことがわかります。
![\[ KL(p(x)|q(x;\theta)) = \int p(x) \log p(x) - \int p(x) \log q(x;\theta) \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-71af12a0e6cd605f4d46ac2c6c9f6f9d_l3.png "Rendered by QuickLaTeX.com")
この第2項
![\[\int p(x) \log q(x;\theta)\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-b3cd91ebb8fe999d7467ede846265e8c_l3.png "Rendered by QuickLaTeX.com")
は真の分布についての対数尤度の期待値、平均対数尤度と呼ばれます。しかし、実世界において積分が達成されることは僕は知らないです。なぜならデータが離散でしか得られないからです。そこで、この項の最大化は以下の平均対数尤度の推定量を最大化させることで近似します。
![\[ \frac{1}{n}\sum_{i=1}^{n}\log q(x) \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-1ac8230b0c4fc9c8a58f87236c159f99_l3.png "Rendered by QuickLaTeX.com")
見ての通り最尤法と等しいということがわかります。
ベイズの定理
根幹とも言えるべイズの定理に触れます。2つの事象 の同時確率を考えるとこれは
の同時確率を考えるとこれは が起きてかつ
が起きてかつ も起きる確率なので
も起きる確率なので
![\[ P(A,B) = P(B|A)P(A) \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-fdc50e5f318128bfd086bfb2e92acaf2_l3.png "Rendered by QuickLaTeX.com")
です。同様に
![\[ P(A,B) = P(A|B)P(B) \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-30a9fb2e4b7430d9414b5c2150ad76f4_l3.png "Rendered by QuickLaTeX.com")
以上の2式より
![\[ P(A|B) = \frac{P(B|A)P(A)}{P(B)} \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-8aab0d5dc9914df523b98d74159cbdc1_l3.png "Rendered by QuickLaTeX.com")
が得られ、これがベイズの定理です。
事前分布と事後分布とMAP推定
上で得た式をよく見ると左辺では 、右辺では
、右辺では とあるため、を用いてを求める定理と理解できます。ここでをパラメータとしをデータ
とあるため、を用いてを求める定理と理解できます。ここでをパラメータとしをデータ とすると
とすると
![\[ P(\theta|D) = \frac{P(D|\theta)P(\theta)}{P(D)} \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-19038589c66e8167b42849a5c0a771c7_l3.png "Rendered by QuickLaTeX.com")
となり、 は事前分布、
は事前分布、 は事後分布呼びます。ちなみに
は事後分布呼びます。ちなみに は尤度ですね。
は尤度ですね。
- 事前分布とは、パラメータに対して事前に仮定する分布です。
- 事後分布とは、取得したデータを用いて事前分布を修正した結果得られるパラメータの分布です。
![\[P(\theta | D) = \frac{P(D|\theta) P(\theta)}{P(D)} = \frac{P(D|\theta) P(\theta)}{ \int_\theta P(D|\theta) d \theta } \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-3d8ab66721c1e7cb01d14b3eac58312c_l3.png "Rendered by QuickLaTeX.com")
MAP推定とは、事後確率(上の式左辺)を最大化させるパラメーターを推定する方法です。事後確率と事後分布は同じようなものと思ってもらって構いません。式をよく見みて、 がに無関係であることに注意するとMAP推定は
がに無関係であることに注意するとMAP推定は
![\[ P(\theta|D) \simeq P(D|\theta)P(\theta) \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-d27b93a87400db7e43ba8bc271e763da_l3.png "Rendered by QuickLaTeX.com")
を最大化すればいいとわかります。
共役事前分布
ここで事前分布が重要になります。例えば先ほどのコインの例を考えます。表が出る確率をとします。このパラメータの分布が事前分布です。注意してください、確率ではなく分布です。普通の人なら表も裏も同じくらい出やすいと考えますよね?結果的に事前分布は一様分布になります。サイコロも同じです。普通なら全ての目が同じくらい出やすいと思うので事前にパラメータに与える分布は一様分布になります。
このように事前分布は人間が最初に設定してあげるものなのです。しかし、よくみてください、積分があるんです。前述通り積分はやばいんです。なのでたまに数値計算で対処します、それが噂のMCMCとかです。
しかし、MCMCは僕には難しい、、なんとか計算したい、、そこで
計算を簡単にするために共役事前分布という特別な性質を持った分布を事前分布に使う習慣があります。共役事前分布とは、事前分布と事後分布が同じ形になるもののことです。
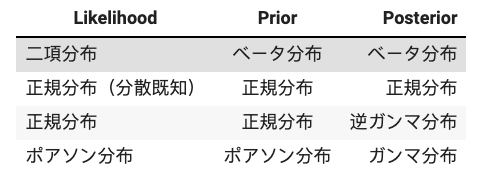
MAP推定の例
二項分布の場合には尤度は
![\[ P(D|\theta) = \Pi_{i=1}^{n}\theta^{x_i}(1-\theta)^{1-x_i} \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-58e7920e3dbc992eecb26b15b1acaf04_l3.png "Rendered by QuickLaTeX.com")
であり、事前分布には以下のベータ分布が用いられます(ちなみにこれをマルチにしたものがディリクレ分布とかの話です)
![\[ Beta(\theta|a,b) = \frac{\Gamma(a+b)}{\Gamma(a)\Gamma(b)}\theta^{a-1}(1-\theta)^{b-1} \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-72a476f4e092bf953a9f08354d0e2f7a_l3.png "Rendered by QuickLaTeX.com")
ここで というガンマ関数です。これらを用いると事後分布は
というガンマ関数です。これらを用いると事後分布は
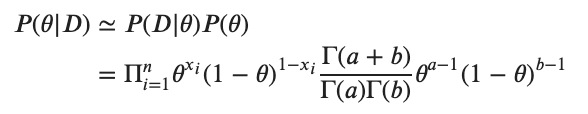
となるが は
は であるのでたとえば
であるのでたとえば
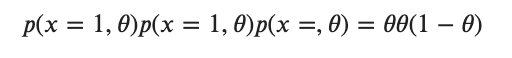
となるので
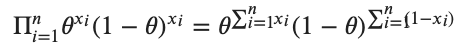
を用いると先ほどの事後分布は以下のように変形されます
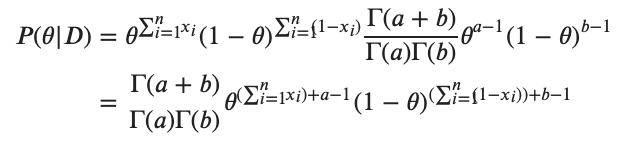
ここでガンマ関数の項は定数項なので無視すると結局ベルヌーイにおけるMAP推定は以下の最大化に帰着します
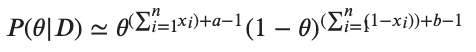
これより事前分布に共役事前分布を用いることにより確かに、事後確率が先ほどの尤度からほとんど形が変わっていないことがわかりました。この例では が
が 回、
回、 が
が 回それぞれ多く出た形になってます。
回それぞれ多く出た形になってます。
思い出してください、事前分布は我々が選びます。つまり我々の意思を事前分布として反映させられるのです。つまりベルヌーイ分布に対してベータ分布という共役事前分布なるものを導入した場合には、この を適当に調整することによって、もともとコインがどれだけ偏っていそうかという主観を反映できるというのです。
を適当に調整することによって、もともとコインがどれだけ偏っていそうかという主観を反映できるというのです。
このように、勝手に設定できる(しなければならない)パラメータ(今回は)のことをハイパーパラメータと呼びます。
長くなりましたが実際にMAP推定を行っていきましょう。最尤推定と同様に対数をとりましょう、これで計算が楽になります。
![\[\log P(\theta|D) \simeq {(\sum_{i=1}^{n}x_i)+a-1}\log \theta + {(\sum_{i=1}^{n}(1-x_i))+b-1}\log (1-\theta) \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-fdb38523124a42cd936862047ca7a3e7_l3.png "Rendered by QuickLaTeX.com")
の形で表すことができます。あとはこの式をで微分して を解けばよいので
を解けばよいので
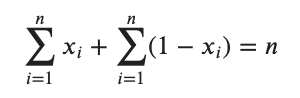
に注意すると最適解は
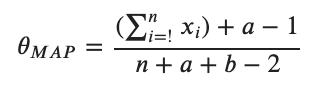
と簡単にもとまりました。
MAP推定までやりましたが僕的にMAP推定はそれほど重要ではありません。次にやるベイズ推定をセットでやるとそれぞれの立ち位置的なものがわかります。ですので今回は「MAP推定って事後分布を最大化させるパラメータ探しやねんぁ」くらいにしておいてください。ついでにKLの記事も読んでください。
参考文献
- https://research.miidas.jp/2019/04/klとnllの関係とか/
- https://research.miidas.jp/2019/04/エントロピーとklについて/
- https://research.miidas.jp/2019/09/なぜklを最小化するのか?/