本日はEMアルゴリズムについてお話ししようと思います。「EMアルゴリズム?」と思った方へ先に簡単に紹介すると
Expectation-Maximization Algorithm
の略で、潜在変数(Z)を用いて、iterativeに尤度最大化を行う手法です。iterativeというのはE-step、M-stepと言われる2種類を交互に行い尤度を最大化し、パラメータを決定します。2ステップに分けて行うことがミソなんですけれど数式ゴリゴリすると途中で自分が何をやっていたかわからなくなるんですよね。その点に注意しながら進めていこうと思います。Notation
 個の独立なデータ(observable)、
個の独立なデータ(observable)、
- モデルのパラメータ、

- 潜在変数(unobservable)、

![\[l(\theta) = \sum_{i=1}^{m} \log p(x^{i};\theta) = \sum_{i=1}^{m}\log \sum_{z}^{}p(x^{i},z;\theta)\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-e14c8b7e1b6447ec3f880ef780a09860_l3.png "Rendered by QuickLaTeX.com")
 を満たすとある確率分布
を満たすとある確率分布 を用いて下界を導出します。
を用いて下界を導出します。
![\[= \sum_{i}^{}\log\sum_{z^{(i)}}^{}Q_i(z^{(i)})\frac{p(x^{i},z^{(i)};\theta)}{Q_i(z^{(i)})}\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-707c2f13fa25a463dd246c7b1a588856_l3.png "Rendered by QuickLaTeX.com")
![\[\geq \sum_{i}^{}\sum_{z^{(i)}}^{} Q_i(z^{(i)})\log\frac{p(x^{i},z^{(i)};\theta)}{Q_i(z^{(i)})}\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-3383e605e646dac5b117a4d3f4f7d2f2_l3.png "Rendered by QuickLaTeX.com")
 を区間
を区間 上で定義される凸関数とする。以下が満たされるとき
上で定義される凸関数とする。以下が満たされるとき


 ,
,
![\[f\left (\sum_{i=1}^{n}\lambda_i x_i\right) \leq \sum_{i=1}^{n}\lambda_if(x_i)\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-ae594d8e85ac8499e15ba4ad4e4030b9_l3.png "Rendered by QuickLaTeX.com")
![\[In\sum_{i=1}^{n} \lambda_i x_i \geq \sum_{i=1}^{n} \lambda_i In(x_i)\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-27cfcaae502afcc9541e92353afb58d2_l3.png "Rendered by QuickLaTeX.com")
![\[ \frac{p\left(x^{i}, z^{(i)} ; \theta\right)}{Q_{i}\left(z^{(i)}\right)}=constant\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-cc24d76cb802a6cb7643feee93485f84_l3.png "Rendered by QuickLaTeX.com")
![\[ Q_{i}\left(z^{(i)}\right) \propto p\left(x^{i}, z^{(i)} ; \theta\right)\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-2c4faeed4e876fd9b6bf261b98003e82_l3.png "Rendered by QuickLaTeX.com")
の性質、 を用いると
を用いると
![\[Q_i(z^{(i)}) = \frac{p(x^{i},z^{(i)};\theta)}{\sum_z p(x^{i},z;\theta)}\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-5c9eb8d890ad0ee2be51b168be86040e_l3.png "Rendered by QuickLaTeX.com")
![\[= \frac{p(x^{i},z^{(i)};\theta)}{p(x^{i};\theta)}\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-b56d0bb76cd65438d7a8477d0f9e0ada_l3.png "Rendered by QuickLaTeX.com")
![\[= p(z^{(i)}|x^{i};\theta)\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-ac896760055b3256a39e379ebc2697e7_l3.png "Rendered by QuickLaTeX.com")
が求まりました。コレがE-stepです。M-stepは下界の最大化です。つまり
![\[ \theta :=\arg \max_{\theta} \sum{i} \sum_{z^{(i)}} Q_{i}\left(z^{(i)}\right) \log \frac{p\left(x^{i}, z^{(i)} ; \theta\right)}{Q_{i}\left(z^{(i)}\right)}\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-1b56b4942df4daceb0dfd623b4eff6ec_l3.png "Rendered by QuickLaTeX.com")
- 潜在変数の事後確率計算
- パラメータの更新
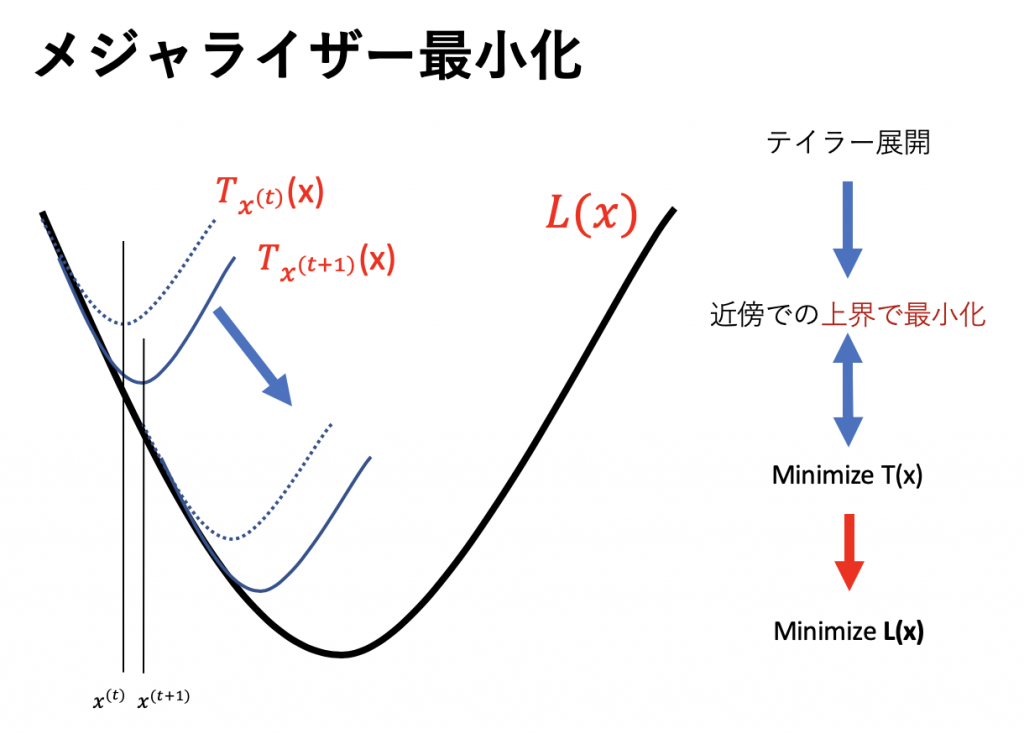
では、コレで下界の最大化ができたことになりますがその際、本来の目的関数、つまり
 も同時に最大化されているのでしょうか?ではステップを
も同時に最大化されているのでしょうか?ではステップを とし、
とし、 で確認してみます。
で確認してみます。 とすることでイェンセンの等式は保持されるので
とすることでイェンセンの等式は保持されるので
![\[ l\left(\theta^{(t)}\right)=\sum_{i} \sum_{z^{(i)}} Q_{i}^{(t)}\left(z^{(i)}\right) \log \frac{p\left(x^{i}, z^{(i)} ; \theta^{(t)}\right)}{Q_{i}^{(t)}\left(z^{(i)}\right)}\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-826673014936930e1eae3a7d56b85046_l3.png "Rendered by QuickLaTeX.com")
![\[ l\left(\theta^{(t+1)}\right) \geq \sum_{i} \sum_{z^{(i)}} Q_{i}^{(t)}\left(z^{(i)}\right) \log \frac{p\left(x^{i}, z^{(i)} ; \theta^{(t+1)}\right)}{Q_{i}^{(t)}\left(z^{(i)}\right)}\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-618022ae2174bc0d388e9769bfc6fb5f_l3.png "Rendered by QuickLaTeX.com")
![\[ \geq \sum_{i} \sum_{z^{(i)}} Q_{i}^{(t)}\left(z^{(i)}\right) \log \frac{p\left(x^{i}, z^{(i)} ; \theta^{(t)}\right)}{Q_{i}^{(t)}\left(z^{(i)}\right)} = l(\theta^{(t)})\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-f765bc6e28220507ffd737ff9e487ed3_l3.png "Rendered by QuickLaTeX.com")
EMとKL
先ほどのこの式 ![\[ \sum_{i} \log p\left(x^{i} \theta\right) \geq \sum_{i} \sum_{z^{(i)}} Q_{i}\left(z^{(i)}\right) \log \frac{p\left(x^{i}, z^{(i)} ; \theta\right)}{Q_{i}\left(z^{(i)}\right)}\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-dce1249154d83359da34dd15b1ff0ce0_l3.png "Rendered by QuickLaTeX.com")
![\[L(X, Z, \theta) &=\ln p(X ; \theta)-\sum_{Z} Q(Z) \operatorname{In} \frac{p(X, Z ; \theta)}{Q(Z)}\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-47c21a290f0f4f17bbff7bbe26dd2305_l3.png "Rendered by QuickLaTeX.com")
![\[= \ln p(X ; \theta) \sum_{Z} Q(Z)-\sum_{Z} Q(Z) \operatorname{In} \frac{p(X, Z ; \theta)}{Q(Z)}\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-77c34193422943e0626f7247e5d64856_l3.png "Rendered by QuickLaTeX.com")
![\[= \sum_{Z} Q(Z) \ln p(X ; \theta)-\sum_{Z} Q(Z) \ln \frac{p(X, Z ; \theta)}{Q(Z)}\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-0f5617589f6193345598e3c977a55a97_l3.png "Rendered by QuickLaTeX.com")
![\[= \sum_{Z} Q(Z) \ln p(X ; \theta)-\sum_{Z} Q(Z)\left{\ln \frac{p(Z | X ; \theta) p(X ; \theta)}{Q(Z)}\right\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-5c037a4115cd76e96070f1b8ed5c4cf2_l3.png "Rendered by QuickLaTeX.com")
![\[=-\sum_{Z} Q(Z) \ln p(X ; \theta)-\sum_{Z} Q(Z){\ln p(Z | X ; \theta)+\ln p(X ; \theta)-\ln Q(Z)}\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-22f3535a3458c72cdd884b862b3cd0e2_l3.png "Rendered by QuickLaTeX.com")
![\[=-\sum_{Z} Q(Z) \ln p(X ; \theta)-\sum_{Z} Q(Z){\ln p(Z | X ; \theta)+\ln p(Z))\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-35fc3d16811e9b6c93551f0f2df1fcca_l3.png "Rendered by QuickLaTeX.com")
![\[=K L[Q(Z) | p(Z | X ; \theta)-\ln Q(Z))\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-34a6745f17aefbad40d3583cbb42327b_l3.png "Rendered by QuickLaTeX.com")
![\[ \ln p(X ; \theta)=\sum_{Z} Q(Z) n \frac{p(X, Z ; \theta)}{Q(Z)}+K L[Q(Z) | p(Z | X ; \theta)]\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-c08041ea625ac900deff0c386b22dcf5_l3.png "Rendered by QuickLaTeX.com")
 ということですが先ほどと同じ結果が得られていますね。
ということですが先ほどと同じ結果が得られていますね。今回はEMアルゴリズムをもとに数式をずらずらとやってみました。日本の大学はレジュメも講義もほとんど公開してないですね、、
References
- https://www.cs.utah.edu/~piyush/teaching/EM_algorithm.pdf
- http://www.princeton.edu/~amirali/Public/Teaching/ORF523/S16/ORF523_S16_Lec7_gh.pdf
- http://pianopiano.sakura.ne.jp/ml/em-algorithm/
- https://oimeg.blogspot.jp/2015/07/em.html
- https://en.wikipedia.org/wiki/Convex_function
- https://mathtrain.jp/jensen_proof
- http://cs229.stanford.edu/notes/cs229-notes8.pdf
- https://math.stackexchange.com/questions/628386/when-jensens-inequality-is-equality
- https://qiita.com/kenmatsu4/items/59ea3e5dfa3d4c161efb
- https://math.stackexchange.com/questions/247795/what-is-the-covariance-of-mixture-bernoulli-distribution