こんにちは。
前回の最後に、
– Coordinate descent(座標降下法)
– ISTA (メジャライザー最小化)
– FISTA (高速化)
の3つの最適化方法を紹介しました。今回は上の2つを解説します。そして次回実装へうつりましょう。
まずは簡単なLassoからです。
Coordinate descent
いきなり解説に入る前に何ですが、座標降下法ってメチャクチャシンプルなんですよ。
けど全く有名じゃないんですよね。(多分、理由は記事の最後)まあ、アルゴリズムみましょう
目的関数 の最適化を考えます。
の最適化を考えます。
ここで はconvexかつdifferentiabl、
はconvexかつdifferentiabl、 はconvexとします。
はconvexとします。
(例えばconvexかつundifferentiablな を考えた場合、反例があります。詳しくはREADMORE)
を考えた場合、反例があります。詳しくはREADMORE)
 回目の更新を右肩の添え字で表すと、各変数に対して
回目の更新を右肩の添え字で表すと、各変数に対して
![\[x_1^{(k)} = \texttt{argmin } f(x_1, x_2^{(k-1)}, x_3^{(k-1)}, \cdots, x_n^{(k-1)})\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-a208013dfcbe0947f48a968c4a613478_l3.png "Rendered by QuickLaTeX.com")
![\[x_2^{(k)} = \texttt{argmin } f(x_1^{(k-1)}, x_2, x_3^{(k-1)}, \cdots, x_n^{(k-1)})\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-3d5776006235d456d856ad651ea5b42c_l3.png "Rendered by QuickLaTeX.com")
![\[x_3^{(k)} = \texttt{argmin } f(x_1^{(k-1)}, x_2^{(k-1)}, x_3, \cdots, x_n^{(k-1)})\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-7b54b8a1d060aeee6942160fb3e9021a_l3.png "Rendered by QuickLaTeX.com")
のように更新するアルゴリズムです。
Pointは1つ、変数を1つずつ更新するんです。その他の変数は定数とみるんです。なので
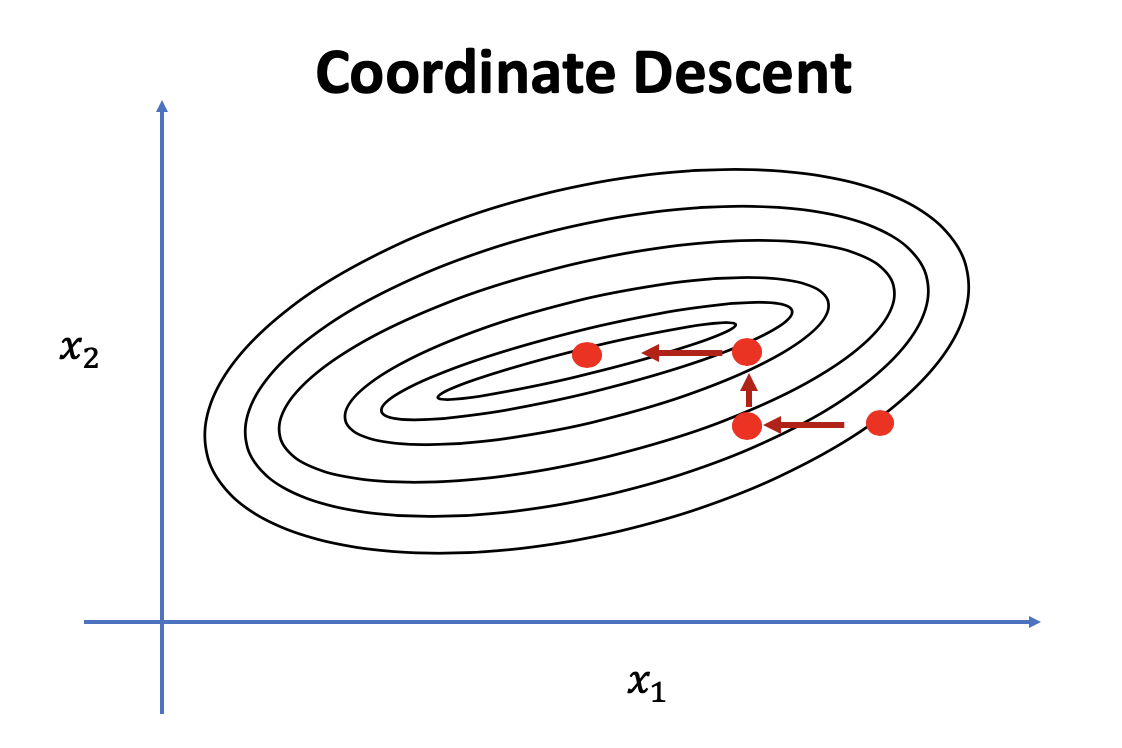
この図の感じですね。しかし次の問題を考えてみましょう に対して
に対して
![\[\texttt{Minimize } x_1^2 + x_2^2 + 5|x_1 + x_2|\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-6546500fdca81d923c3fff02783e16a9_l3.png "Rendered by QuickLaTeX.com")
です。例えば初期値を で座標降下法をアプライしてみると
で座標降下法をアプライしてみると
 のどちらから更新してもで停滞することがわかります。しかし
のどちらから更新してもで停滞することがわかります。しかし
これは明らかに最適解は ですよね。こういったことからスパースな問題にはあまり良くないようです。
ですよね。こういったことからスパースな問題にはあまり良くないようです。
次にメジャライザーの方を行きましょう。
Iterative Shrinkage Thresholding
ちなみにこのアルゴリズムは初めて聞きました。EMアルゴリズムでも似たことが行われますね。
こちらもアルゴリズムは単純で
というものです。
一次元の場合、 を
を 周りでのテイラー展開
周りでのテイラー展開
![\[f(x) \approx f(a) + f^{(1)}(a)(x-a) + \frac{1}{2!} f^{(2)}(a)(x-a)^2 + \frac{1}{3!} f^{(3)}(a)(x-a)^3 + \cdots\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-889a2ae66f0888a1db506e3258d09141_l3.png "Rendered by QuickLaTeX.com")
多次元の場合、
![\[f(\vc{x})= f(x_1,x_2, \ldots, x_n)\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-6afc56b7b4c3bcd4c22486bea9206956_l3.png "Rendered by QuickLaTeX.com")
![\[f(\bf{x}) \approx f(\bf{a}) + Df(\bf{a}) (\bf{x}-\bf{a}) + \frac{1}{2} (\bf{x}-\bf{a})^T Hf(\bf{a}) (\bf{x}-\bf{a})\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-5cb7c6457dfffaa557194525d8fcc835_l3.png "Rendered by QuickLaTeX.com")
下の図がイメージになります。上界というのは「より大きいやつ」という意味です。
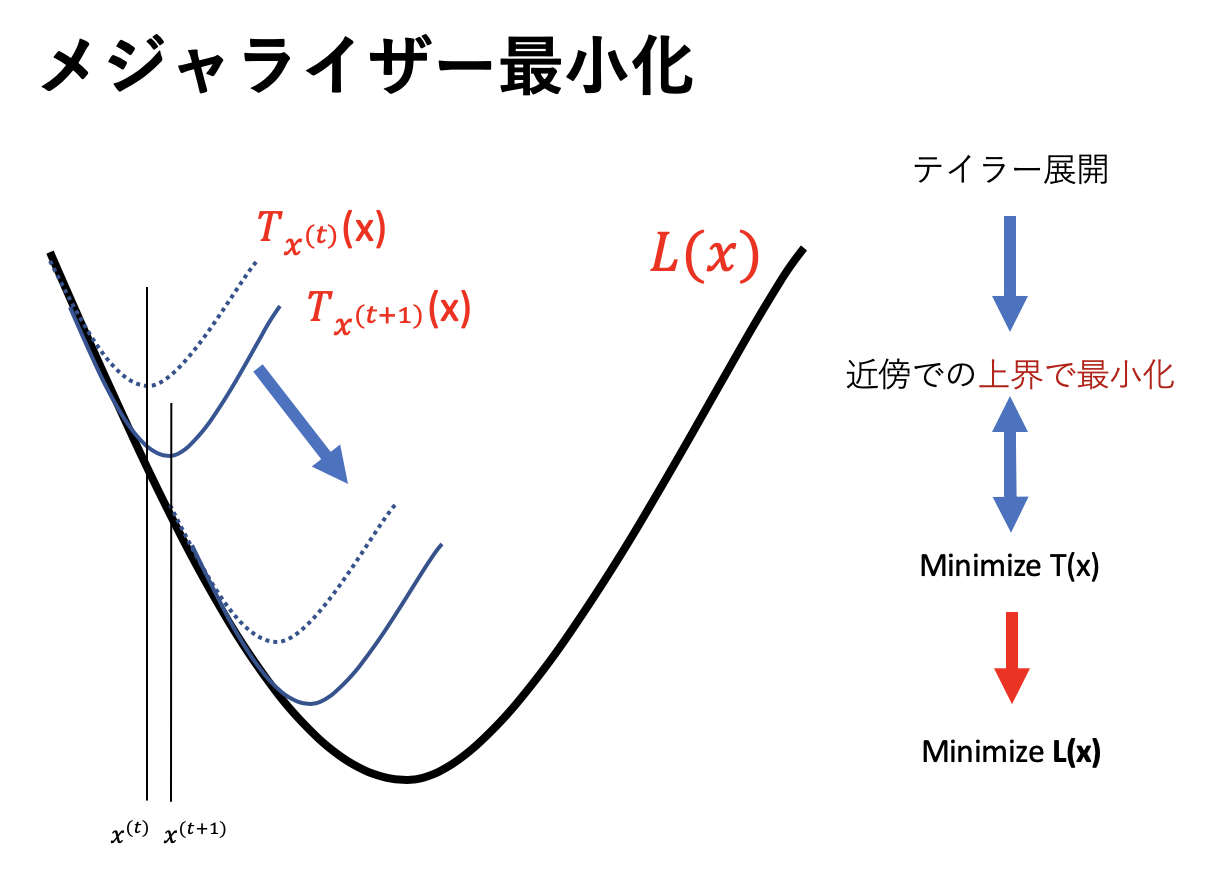
この図からアルゴリズムがどうやって動いて何で最適化できるのかは直感的にわかったかと思います。
しかし、このメジャライザーが本当に存在するのか?など疑問に思う人がいるでしょう。
では考察しましょう。
まず初期値を とします。そして目的関数を
とします。そして目的関数を ,メジャライザーを
,メジャライザーを とします。
とします。
そして、メジャライザーは次のような性質を満たしてほしいです。
– 
–  に対して
に対して 
すると性質から明らかに の最小化が
の最小化が の最小化に繋がることがわかります。
の最小化に繋がることがわかります。
では実際にそんな都合のいいを探しましょう。の前にちょっと寄り道します。
どんな形のメジャライザーが都合いい?
メジャライザー を探すといえどこのままでは全くわかりません。
を探すといえどこのままでは全くわかりません。
 にすればいいのか?いや、それもわかりません。なので
にすればいいのか?いや、それもわかりません。なので
いきなりですが次の最適解 を考えましょう。次元は1です。(
を考えましょう。次元は1です。( )
)
![\[\texttt{argmin } \frac{1}{2} (y-x)^2 + \lambda |x|\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-776b0813cf88c9daf963324f9a6cf3bb_l3.png "Rendered by QuickLaTeX.com")
前回の記事でやったようにこれは場合分けで簡単にできますね
 に対して
に対して
![\[\frac{1}{2} (x^2 - 2xy + y^2 + 2\lambda x) = \frac{1}{2} (x - (y-\lambda))^2 + \texttt{const}\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-e9790eb314fc9683735f08901f8b8bf9_l3.png "Rendered by QuickLaTeX.com")
同様にして に対して
に対して
![\[\frac{1}{2} (x - (y+\lambda))^2 + \texttt{const}\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-2576ea975b0fc8fc6d3cd88b36562870_l3.png "Rendered by QuickLaTeX.com")
では最後に の範囲で場合分けすると前回のSoft thresholding functionが出てきましたね。
の範囲で場合分けすると前回のSoft thresholding functionが出てきましたね。
![\[x = S ( y, \lambda )\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-6d6dbbb30ded7c140e8e15610c006ef1_l3.png "Rendered by QuickLaTeX.com")
詳しく復習すると
 の時
の時
![\[x= y + \lambda\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-42044550dbabed3caf00f4859aa7c22d_l3.png "Rendered by QuickLaTeX.com")
 の時
の時
![\[x = 0\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-f4d5e67d4db59ebeb86c661dd9eb518c_l3.png "Rendered by QuickLaTeX.com")
 の時
の時
![\[x = y - \lambda\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-8624504308b595bb55767e351a3997f4_l3.png "Rendered by QuickLaTeX.com")
これが大切です。
ではLassoの目的を再掲しましょう。
![\[\texttt{argmin } ||y - Xb||_2^2 + \lambda|b|_1^1\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-11ac5cb3484e8c113bc242655dcbba71_l3.png "Rendered by QuickLaTeX.com")
今の例と似てますよね。
ここで
これがほしいメジャライザーを予測するということです。
では元に戻って都合のいいを探しましょう。平方完成できるやるがいいんでしたね。
テイラーの2次近似の形を想像しながら
![\[\mathcal{T}(\mathbf{x}) = \mathcal{L}(\mathbf{x}^{(t)}) + \frac{d\mathcal{L}(\mathbf{x}^{(t)})}{d\mathbf{x}}(\mathbf{x} - \mathbf{x}^{(t)}) + \frac{\rho}{2}\bigl\vert\mathbf{x}-\mathbf{x}^{(t)}\bigr\vert^2\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-a07b78c9f4ce05d391daa76dbd9c394b_l3.png "Rendered by QuickLaTeX.com")
という形で考えましょう、( は計算の都合上のもの)そうすれば
は計算の都合上のもの)そうすれば
![\[= \frac{\rho}{2} \Bigl\vert \bigl( \mathbf{x}^{(t)} - \frac{1}{\rho} \frac{d\mathcal{L}(\mathbf{x}^{(t)})}{d\mathbf{x}}\bigr) - \mathbf{x} \Bigr\vert^2 + \texttt{const}\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-4061dafe930ed2a3f9ccd4ffc1166c52_l3.png "Rendered by QuickLaTeX.com")
とできますね。よって
![\[\text{argmin } \Bigl(\mathcal{T}(\mathbf{x}) + \lambda |\mathbf{x}|\Bigr)\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-53b80f1d717421352503c194ffbd5d76_l3.png "Rendered by QuickLaTeX.com")
は
![\[x^{(t+1)} = S \Bigl( \frac{1}{\rho} \frac{d\mathcal{L}(\mathbf{x}^{(t)})}{d\mathbf{x}}, \lambda \Bigr)\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-e602547bc759dea108ac9c9d6eadca64_l3.png "Rendered by QuickLaTeX.com")
となります。
そうなんです。先ほどメジャライザーを考えたときに を使いましたね。
を使いましたね。
このを決める必要があります。メジャライザーの性質(2)から
![\[\mathcal{T}(\mathbf{x}) - \mathcal{L}(\bf{x}) = \frac{1}{2} (\bf{x} - \bf{x}^{(t)})^\top (\rho I - X^TX) (\bf{x} - \bf{x}^{(t)})\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-7ac85ffcc827e9afb4115285109b5c8e_l3.png "Rendered by QuickLaTeX.com")
が「0以上」を任意の について言える必要があるので
について言える必要があるので
 が半正定値
が半正定値の必要があります。つまり、 の最大の固有値がとして取りうる最小の値になります。
の最大の固有値がとして取りうる最小の値になります。
そこで固有値の大きさを見積れる定理があるのでそれを使いましょう。
– Gershgorin circle theorem
– Gershgorin’s Theorem for Estimating Eigenvalues
この定理からmaxをとることで
![\[\texttt{eigenvalue } \le \max_j \sum_i\bigl\vert{\mathrm{X^\top X}}_{ij}\bigr\vert\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-a38448914597dde4939dd76fcbcdf83b_l3.png "Rendered by QuickLaTeX.com")
と固有値の大きさが見積もれます。
長かったですがとりあえずLassoはおしまいです。
でわ。