こんにちは。
素人にfish_shellは無理でした。kzです。
リッジが終わりましたね。ついに来ました
ラッソ
最近色々ラッソについて調べていたんですが、微分不可能な関数の最適化ってやっぱ難しいですね。機械学習において非常に重要な2つのキーワード
– ラグランジュの未定乗数法
– KKT条件
は別の記事でゆっくり解説します。では本題に入りましょう。
Lasso
過学習を考慮した回帰モデルの一つ
– L_1正則化項を使用した回帰model
– スパース性を考えるときに用いる(これについては次の記事で詳しく説明します。)
(1) 
リッジ回帰との唯一の違いは正規化項がL1(絶対値)であるということ。
微分できない?
ちょっと微分について復習しよう。おまけで複素解析も出てくるよ
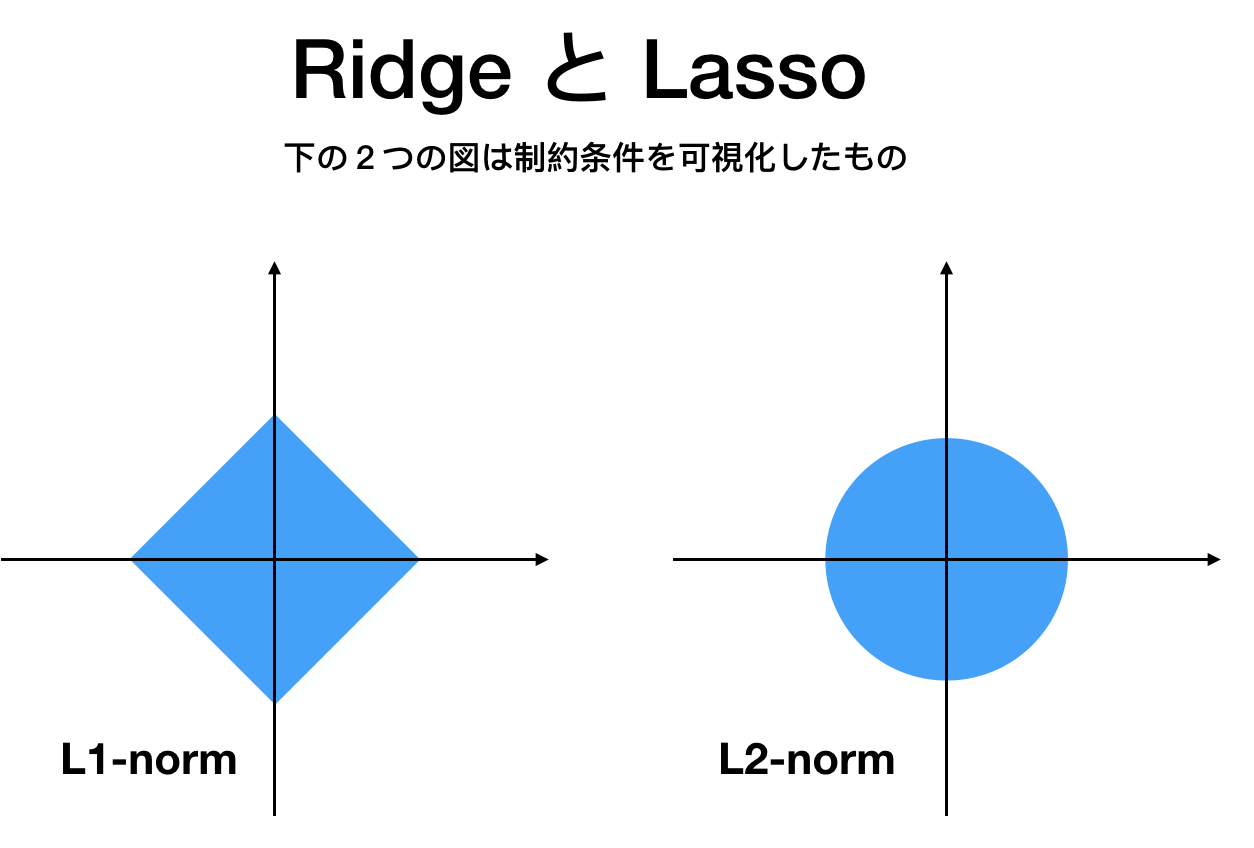
L1とL2
これまでに何度か説明していると思いますがまずは
– 微分可能性
が大きな違いです。L1は尖っているので0で微分できませんね。
他の違いは?
リッジ回帰ではデカイパラメータ がでかくなりすぎないよう上限を設けましたね。
がでかくなりすぎないよう上限を設けましたね。
ラッソも上限はありますが、ゼロがKEYWORDです。なぜなら
– 無関係な特徴量はゼロで排除する
という特徴があります。ゆえに、モデルで初めに設定したものよりも少ない特徴量で済む可能性があります。これが先ほどのスパース性と言われる所以です。
パラメータが0を図から考察
では図を用いて直感的に理解しましょう。次の図はRidge, Lassoを議論するときに使われるとてもポピュラーなものです。
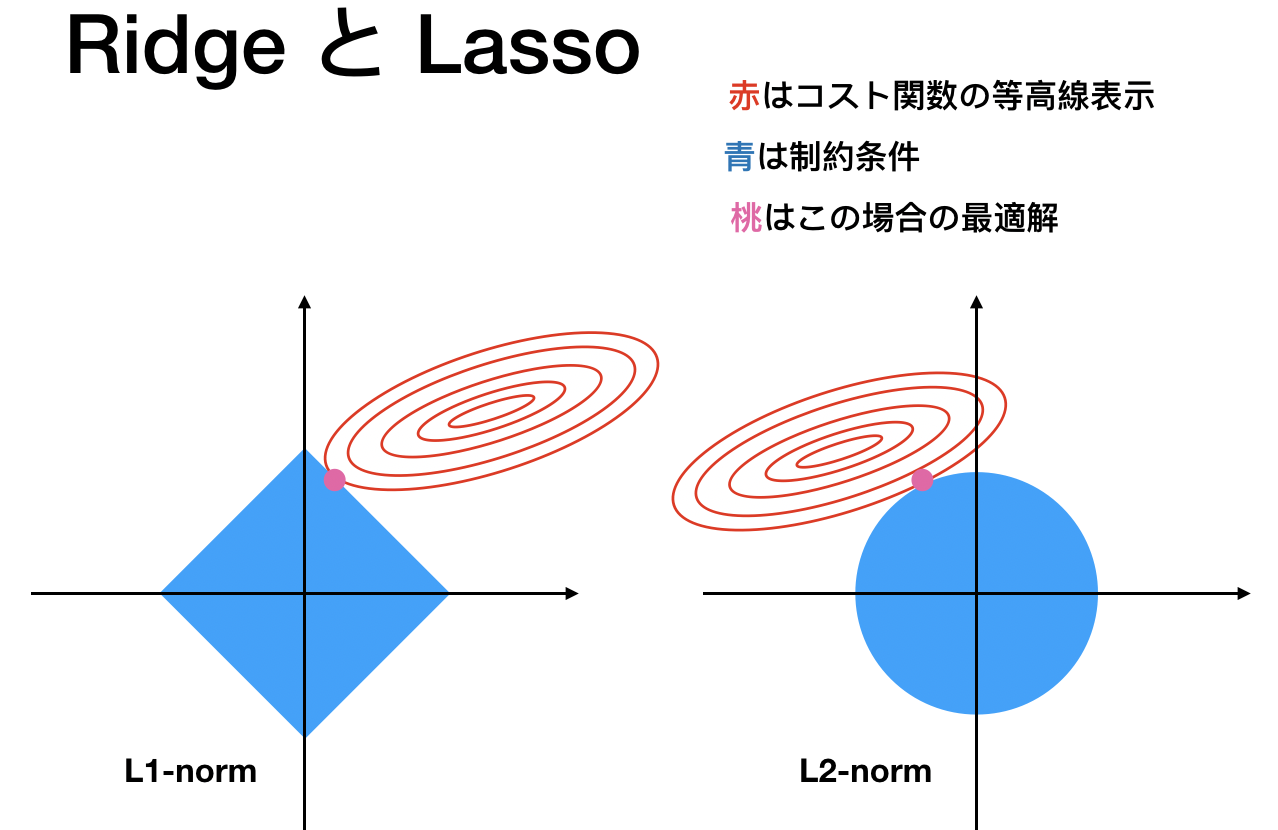
「スパース」とは「スカスカ」なイメージ
つまり、ゼロがいっぱいあるイメージでいい。
しかし重要なのは常にスパースなわけじゃないこと。
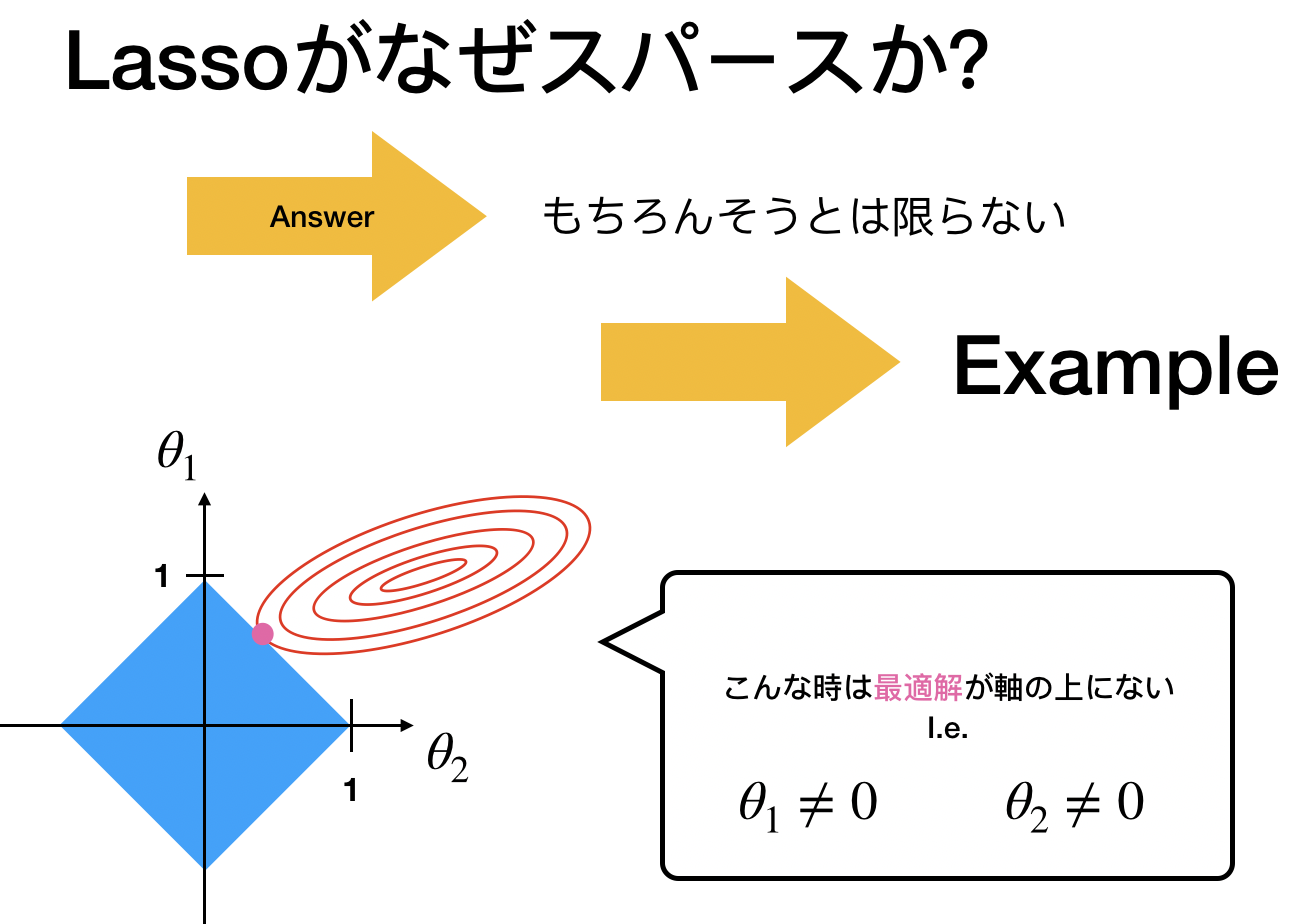
スパースと言われるのはこの「尖ったポイント」に最適解がある時。
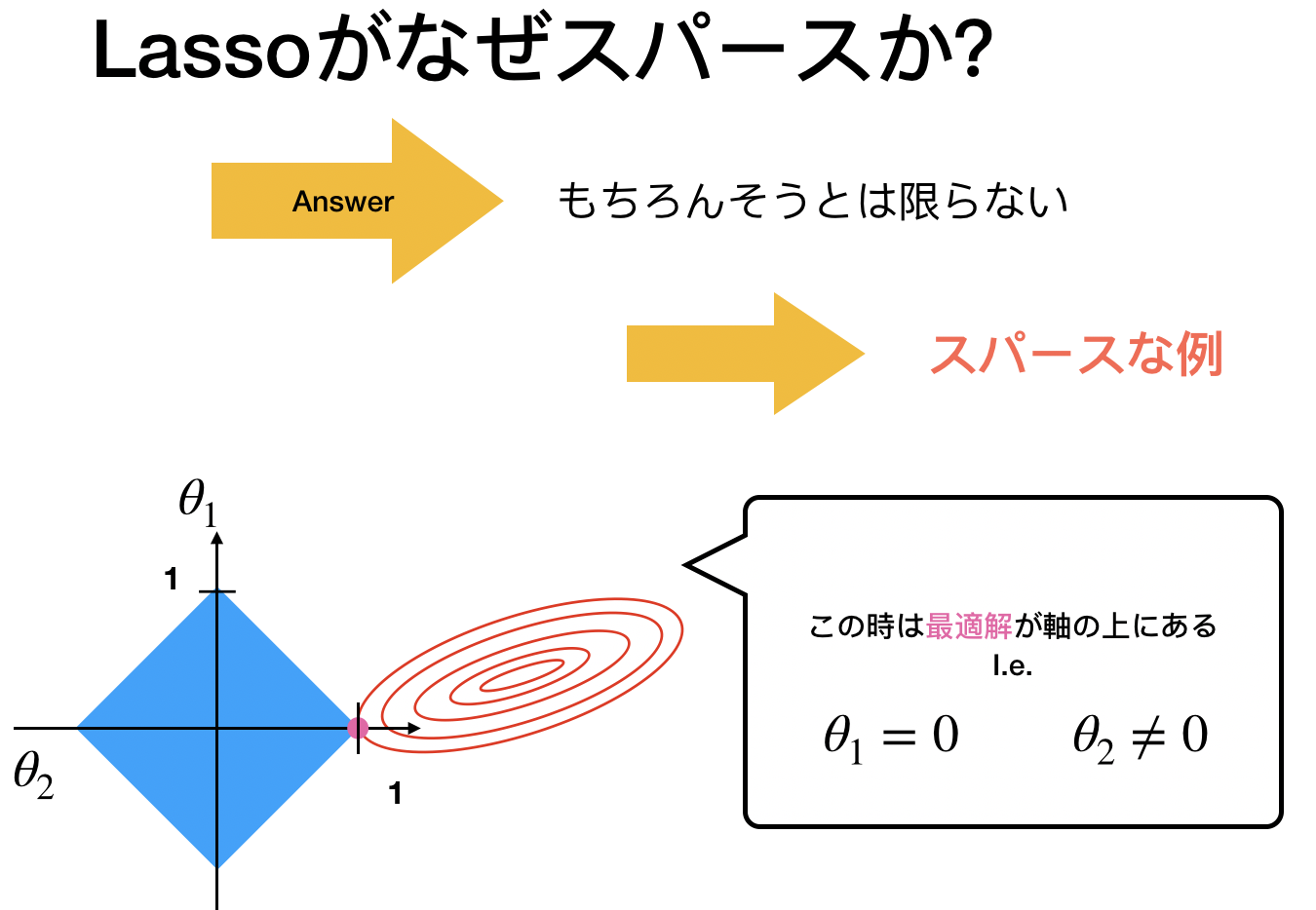
これはL1だからできますよね。L2は円だったのでスパース性はありません。
パラメータが0を数式から考察
次のように超シンプルな回帰モデルを考えます。(以下転置使ってますが無くてもいいです)
(2) 
次の最小化を考えます。
(3) 
(この2は計算の都合上のもの)
ここで解が と仮定します。
と仮定します。
すると、 より
より
 と仮定するのと同値であることがわかります。さて、目的関数をに関して微分しましょう
と仮定するのと同値であることがわかります。さて、目的関数をに関して微分しましょう
仮定より今は微分できます
(4) 
であり、これをゼロと置くことでこの解は次のものだとわかります
(5) 
ここで を増やしていくと
を増やしていくと でゼロになることがわかりますね。
でゼロになることがわかりますね。
この瞬間にLassoはスパース性を持ちます。
一方、リッジの場合は
(6) 
(7) 
となるので、 よりパラメータはゼロにはならないですね。
よりパラメータはゼロにはならないですね。
でわ