こんにちは。
少し前に標準化・正規化についてお話ししました。これらは勾配法による学習の際に学習速度が速くなるというメリットがありました。では今回は
正則化とはなんぞや
名前が似てますね、ということは
勾配法に関係あり?学習速度に関係あり?
いい読みです。次の図を見てください。
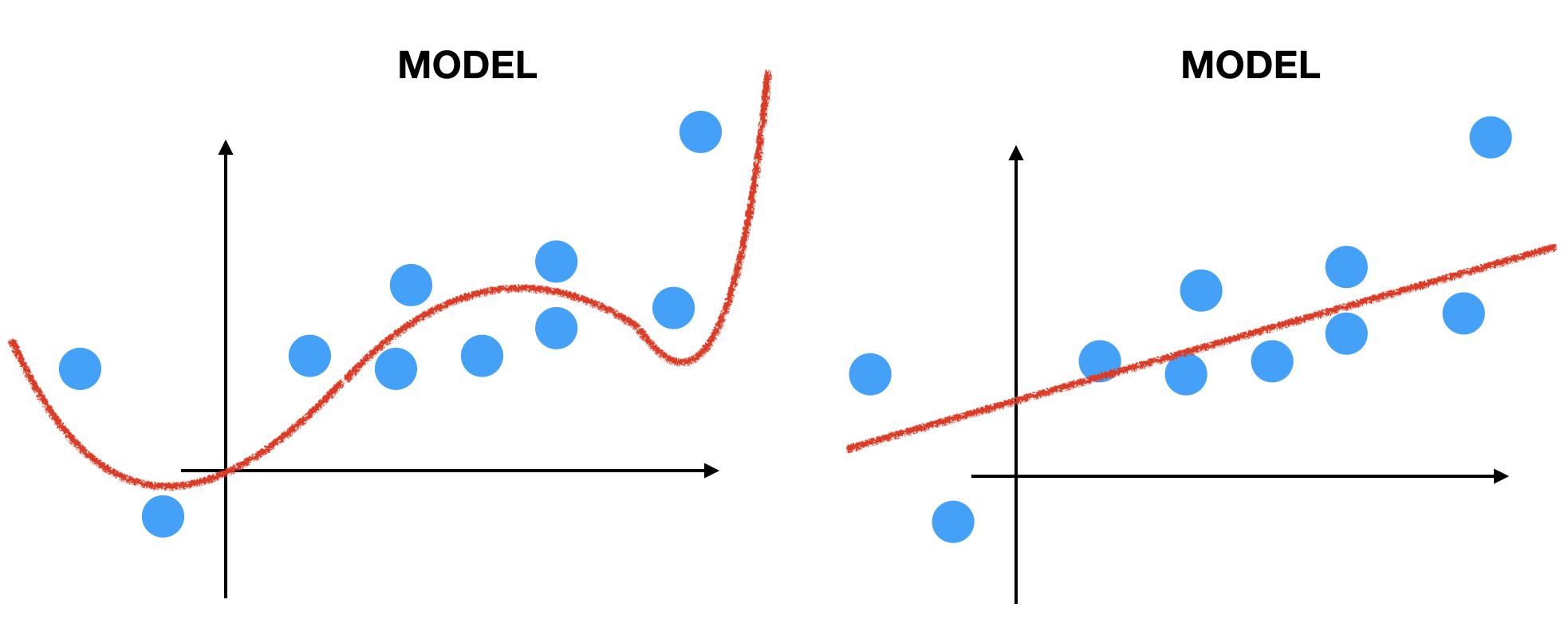
どっちの曲線が「いい学習」をした結果だと思いますか? もう一問
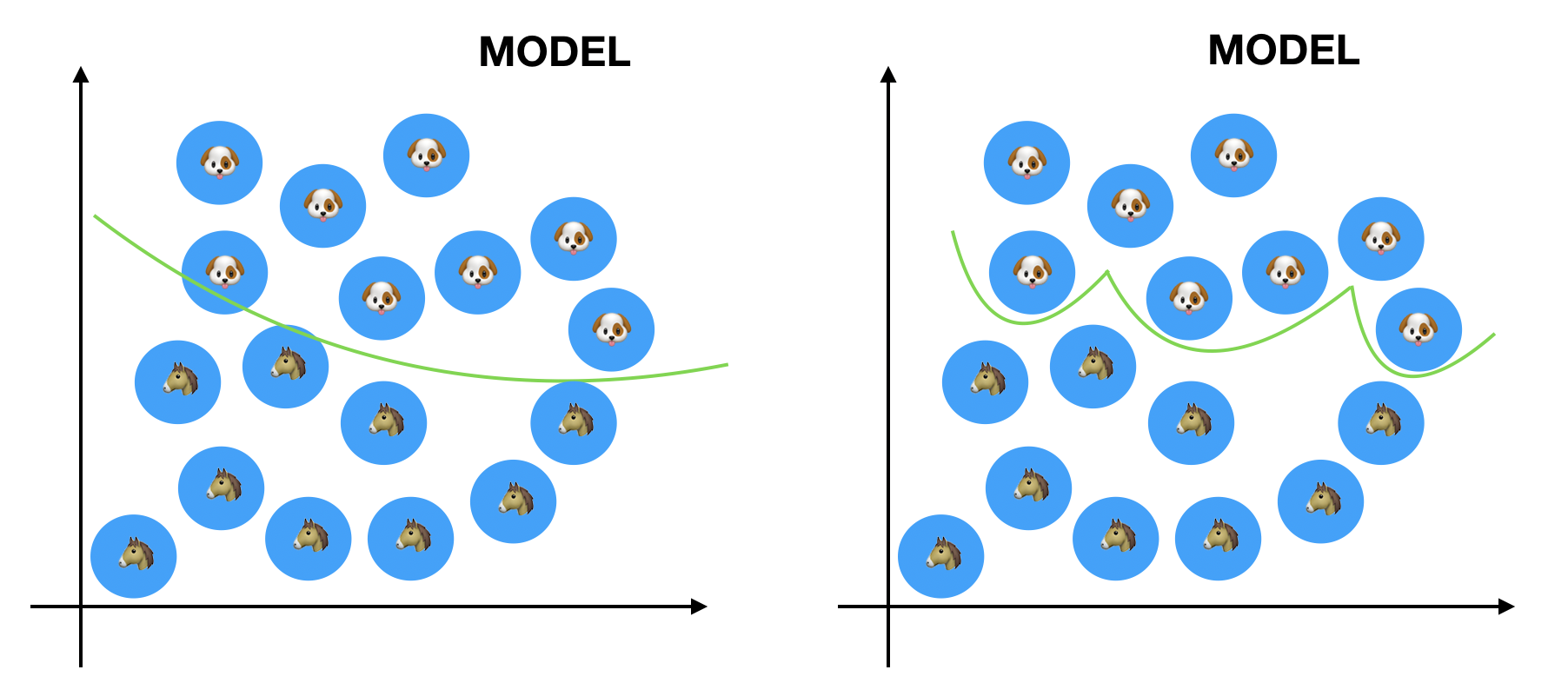
どちらが「いい分類」をしていますか?
「いい分類・いい学習」とは何か?
を考える必要があります。データには誤差がつきものです。なので「誤差を許容するという寛大な心が必要」なんです。つまり、
モデルは柔軟性を持つべき
という考えから「正則化」とう考えに突入します。
具体的には?
そもそもなんで過学習してしまうのか、ですよね。
あるモデルが過学習するということはパラメータが手持ちのデータを重視しすぎるということ
言い換えると
過学習とはモデルが未知のデータを考慮しなくなるということです。
このままではいけません。未知のデータを考慮させる必要があり、そのための作戦が「正則化」です。具体的には
パラメータの学習に制限を設けること
です。例えば、パラメータ を学習させたいとします。そこでモデルを
を学習させたいとします。そこでモデルを 、ラベルを
、ラベルを とでもし
とでもし
![\[|t - F_w(x) |^2 \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-a87aacd0044a037ea6c2046d810e6264_l3.png "Rendered by QuickLaTeX.com")
を最小化することでを学習させる問題を考えます。このままやるとは好き放題学習しますが で
で
![\[|w| \leq \alpha\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-32ab97fb8716c9e96ebcc1e6476924e6_l3.png "Rendered by QuickLaTeX.com")
とかのように制限設けるとはこの範囲で学習しますよね。しかしこれは考える問題が
![\[\texttt{minimize} ~~ |t - F_w(x) |^2 \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-820ac5a94da76c627f55f4585316d78f_l3.png "Rendered by QuickLaTeX.com")
から
![\[\texttt{minimize} ~~ |t - F_w(x) |^2 ~~s.t.~~ |w| \leq \alpha \]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-514d3ea315b70ce414ba78a649bfdd8b_l3.png "Rendered by QuickLaTeX.com")
のように制約付きの最適化問題になりました。ヤバイ、しかも
制約が不等式!!!
これはやばいです。しかし!
KKT条件という物を使えば解決します。(ちなみにSVMとかでも出てきますがかなり難しいです)(ちなみに制約が等式の時はラグランジュの未定乗数法)つまり で
で
![\[\texttt{minimize} ~~ |t - F_w(x) |^2 + \lambda|w|_p\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-08f5d2f0399d8ef4fc49ee0eb73b5d12_l3.png "Rendered by QuickLaTeX.com")
とできます。ただし はLpノルムです。
はLpノルムです。
Lpノルムって何?
 とします、つまり
とします、つまり はn次元実ベクトルとします。この時
はn次元実ベクトルとします。この時 に対して
に対して
![\[| x |_p = \left( |x_1|^p + |x_2|^p + \cdots + |x_n|^p \right)^{1/p}\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-00af3436539ffb0e6760bf0808b44693_l3.png "Rendered by QuickLaTeX.com")
と定義します。これをのLpノルムと言います。関数解析でやるので覚えといて〜。初めての人は直感がわかないと思うので図で見てみましょう。
一般的に使うのは です。少し話が逸れましたが
です。少し話が逸れましたが
これですね。コスト関数を最小化する際にが大きくならないようにペナルティーの形で加えます。なので第二項は罰金項、正規化項などと呼ばれます。これを使った実際の例は次の2つがあります。
- Ridge Regression (Tikhonov regularization)
- Lasso Regression
です。リッジ回帰は 正規化項を使います。なので
正規化項を使います。なので
![\[\texttt{minimize} ~~ |t - F_w(x) |^2 + \lambda|w|_2^2\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-7e4a4bc42d2877ae97285d68fdbeb123_l3.png "Rendered by QuickLaTeX.com")
となります。一方でラッソ回帰は 正規化項を使います。なので
正規化項を使います。なので
![\[\texttt{minimize} ~~ |t - F_w(x) |^2 + \lambda|w|_1^1\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-0f15398ed9d14a119ea270f509f293da_l3.png "Rendered by QuickLaTeX.com")
です。これらについて詳しくは別の記事で書きます。今はとりあえず「正則化」の例として覚えておいてください。
さて、正則化はパラメータの学習に制限を設けることと言いました。で、各ノルムに対する正規化項の特徴についてです。がこれも長くなるので次の記事で会いましょう。
でわ。
READMORE