挨拶
こんにちは。そしてお久しぶりです。数年の時を経た投稿になります。よろしくお願いします。
前書き
データサイエンティストやデータエンジニアに限らずビジネスインテリジェンスユーザーなど時代の趨勢によりあらゆる人がデータに触れる機会が増えてきました。質的データ・量的データなどいろいろなデータがあり、その可視化方法も多種多様です。量的データの分布を可視化する方法として、いちばん最初は度数分布(ヒストグラム)だと思っているひとは多いようです。しかし、僕の身の回りで「最初は経験累積分布(eCDF)を見るよ」っていう人もいます。実際のところ、初手はどちらがよいでしょうか?今回は「ヒストグラムを使うなんてナンセンスだ」という訳ではなく、分布可視化の初手に eCDF がおすすめだよ!という記事を書こうと思います。
本文
Empirical Cumulative Distribution
経験累積分布関数とは empirical cumulative distribution function の直訳であり、これを省略して eCDF と書くことがあります。スカラー実数値確率変数  の密度関数が
の密度関数が  で与えられているとき、(累積)分布関数(cumulative distribution function; CDF) は以下のような積分で定義されます。
で与えられているとき、(累積)分布関数(cumulative distribution function; CDF) は以下のような積分で定義されます。
![\[P(x) = \int_{-\infty}^x p(x) dx\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-9efdb5bdbfac87acd429dc79f70de2fa_l3.png "Rendered by QuickLaTeX.com")
一方で、未知の確率分布に従う実数値スカラーデータ点  が与えられているとき、経験累積分布関数(empirical cumulative distribution function; eCDF)は以下で定義されます。
が与えられているとき、経験累積分布関数(empirical cumulative distribution function; eCDF)は以下で定義されます。
![\[F( x ) = \frac{1}{N} {\rm count}( x_i < x )\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-bc0861e5c7608989afe3b438720f23cf_l3.png "Rendered by QuickLaTeX.com")
ここで  は
は  個のスカラーのなかで 未満のデータ点の個数であり、
個のスカラーのなかで 未満のデータ点の個数であり、 はこれを で割った値です。したがって は最小値 0 最大値 1 をとります。ところで、同様にデータ
はこれを で割った値です。したがって は最小値 0 最大値 1 をとります。ところで、同様にデータ が与えられているとき、以下の確率密度関数
が与えられているとき、以下の確率密度関数  で与えられる確率分布を経験分布(empirical distribution)と呼びます。
で与えられる確率分布を経験分布(empirical distribution)と呼びます。
![\[f(x) = \sum_{i=1}^N \delta(x-x_i)\]](https://research.miidas.jp/wp-content/ql-cache/quicklatex.com-500d326948add9bd99a5ca423d3911e0_l3.png "Rendered by QuickLaTeX.com")
ここで  はデルタ関数と呼ばれ、
はデルタ関数と呼ばれ、 においてのみ正の値
においてのみ正の値 をとり、それ以外で0値をとり
をとり、それ以外で0値をとり 、実数軸上で積分したときに1となるようなものです。eCDF は、この経験分布 を実数軸上で積分したものだと理解することもできます。さらに、右連続と左連続など細かいバリエーションがいろいろあるのですが、今回はそういった部分には触れず、実用的・表面的なところにフォーカスします。
、実数軸上で積分したときに1となるようなものです。eCDF は、この経験分布 を実数軸上で積分したものだと理解することもできます。さらに、右連続と左連続など細かいバリエーションがいろいろあるのですが、今回はそういった部分には触れず、実用的・表面的なところにフォーカスします。
ヒストグラムとeCDF
データ が与えられているとき、これを表すヒストグラムとeCDFを並べて見比べてみましょう。「形・散らばり・位置」に注目して見てください。
四分位範囲の認識
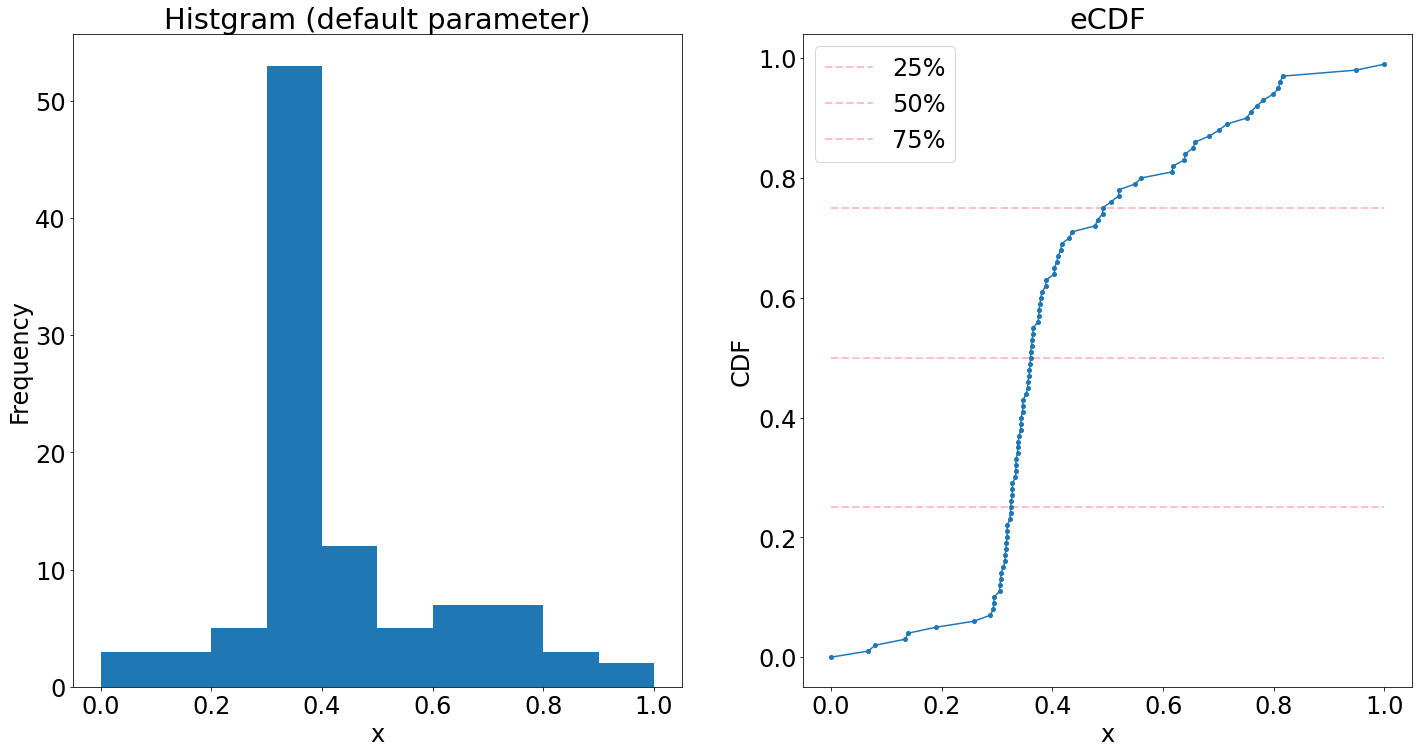
cCDFの強みの一つ目は四分位やパーセンタイルなどの分位点を見やすいことです。右図のピンク線と、eCDF 曲線の交点の x 座標は、この分布の第1,2,3四分位点を表します。同様にして任意の分位点を、図から容易に読み取ることができます。
外れ値のある場合

左パネルのヒストグラムの右端(200<x<210 あたり)に、3点ぶん、外れ値にあたると判定できそうな数値が含まれます。この場合を、eCDFで表すと右パネルのようになります。右パネルでは、赤色のX印 3点が外れ値にあたりそうです。ヒストグラムはビン設定の任意性があるので、ビン幅を大きめにとった場合には外れ値を飲み込んで見えなくしてしまう場合があります。eCDF ではそのような任意性はありません。かんの良い方は気づかれたと思いますが外れ値検出が可能です。関連論文(ECOD: Unsupervised Outlier Detection Using Empirical Cumulative Distribution Functions)もご覧ください。パラメトリックな分布を仮定する必要がないのもいいですね。
分布の特定

分布の形状を比較するとき、ヒストグラムによる比較と、eCDFによる比較とどちらが良いでしょうか? 上の図は一例です。ヒストグラムはビンの設定に依存する一方で、eCDFはその種の依存性はありません。赤と青の分布形状を比較するとき、ヒストグラムで比較するのと、eCDFで曲線の形状を比較するのとで、どちらも一長一短がありそうですね。余裕があれば両方を見るのが良いかもしれません。
参考までに、分布形状がよく知られた分布(例えば正規分布)に従っているか否かを検定する方法として、コルモゴロフ・スミルノフ検定(Kolmogorov Smirnov test)があります。検定によらずに、2つの分布形状の違いを可視化する方法として Q-Q プロットというのもあります。分布形状の比較だけが目的ならば、これらを使うのが良いかもしれません。
上でも述べたようにヒストグラムだとパラメータによって分布を誤って判断してしまう可能性があります。eCDFでは例えばKolmogorov Smirnov testを用いることで正規分布の検定が行えるようです。図中の青はランダムに作ったデータ、オレンジは正規分布から生成したデータになります。
クラスター検出

分布にクラスター構造(データ内部の塊)があるときはどうでしょうか? 例えば男女混合の身長データの分布を考えます。ヒストグラムで見るとき、ビンの設定次第では上図左パネルのように女性の山が155cm、男性の山が170cm二山の構造がきれいに見えますが、設定が悪いと一山にまとまってしまう場合もあります。上図右パネルのeCDFでは設定によらず、曲線の傾きかたからクラスタ構造を見て取ることができます。
固定効果モデルや層別解析の考え方が無意識でできると言えると思います。
分布の比較

パネル分析を扱うことは一般的かと思います。時間と共にデータがどういうふうにシフトしたか、去年との差が知りたい、などの要望もあると思います。eCDFでは同一パネルに複数のグラフを重ねて描くことで、分布の変化を追うことができます。
最後に
上記のように簡単にeCDFの魅力を紹介しました。数理的な面にまで踏み込むことができなくて申し訳ありません。記事内の画像を作るのに使った Python コードはこちらにありますので、参考までに。
ヒストグラムを見比べることに慣れているが、eCDFには慣れていないというひとは多いと思います。ヒストグラムはビン幅を適切に設定すれば見やすいですが、設定を誤るとおかしな結論に導かれてしまう危険もあります。eCDF を読み取るためには慣れる必要がありますが、設定によらず、分布のさまざまな特徴をひと目で見ることができるメリットは明らかです。慣れていないという理由だけで eCDFを使わないのはもったいないですね。設定不要なのですから、「分布を見るなら、初手は eCDF」というやりかたを試してみてはいかがでしょう。
これ以外にも発展としてeCDFを用いた距離などの話があるようです。例えばOptimal Transportで有名な1次元Wasserstein DistanceはCDF間の距離となる?らしいです。ここら辺については機会があればまたまとめようと思います。
僕もまだ理解できていないことが多いのでこんな使い方あるよ!などあればぜひコメントいただきたいです。ありがとうございました。
参考文献
- アーカイブ論文 Unsupervised Outlier Detection Using Empirical Cumulative Distribution Functions
- 書籍 Introduction to Data Science Chapter 9 Visualizing data distributions
- 掲示板 Cross Validated How to measure the shift between two cumulative distribution functions (CDFs)?
- 記事 ANDATA – Why we love the CDF and do not like histograms that much
- 記事 Medium Why ECDF is better than a Histogram | by Shoaibkhanz
- 講義ノート ワシントン大学 Lecture 1: CDF and EDF 1.1 CDF: Cumulative Distribution Function
- 記事 Histograms and CDF’s Part1: What are they?
- 記事 Medium What, Why, and How to Read Empirical CDF
- 資料 データを累積すると見えてくるもの
- アーカイブ論文 Why the 1-Wasserstein distance is the area between the two marginal CDFs
- 記事 Sliced Wasserstein GMM を実装してみた
- Wikipedia Cumulative distribution function
- Wikipedia Empirical distribution function