世の中ではやはり解釈性が重要らしいです。
前回、SHAP含めてモデル解釈の指標についていくつか触れました。やはり一度では僕は残念ながら理解できないので復習も含めて今回この記事を書きます。
前回の復習
上記のリンク先が前回の記事になります。- Permutation Importance
- Partial Dependence
- LIME
- SHAP
ちなみに他にもDrop-Column Importanceとかもあるらしいです。
Feature Importance
順番的には逆になってしまいましたが、決定木自体にはFeature Importanceというものがあります。ご存知ですよね。どうやって算出されてるのや?と思ったので調べました。結論から言えばあまりにも式が複雑で完全に理解し切るのはかなりハードです。。なのでその計算の核となるGini Impurityから始めます。
Gini不純度
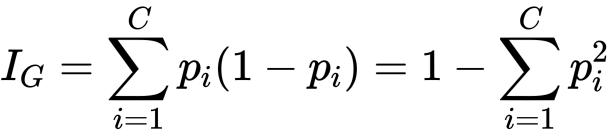
 はクラスの総数
はクラスの総数 はクラスiの割合
はクラスiの割合
二郎系 家系 まぜそば各クラスから均等な量の場合とあるクラスに偏りがある場合
count = 4 4 4
p = 4/12 4/12 4/12
= 1/3 1/3 1/3
GI = 1 - [ (1/3)^2 + (1/3)^2 + (1/3)^2 ]
= 1 - [ 1/9 + 1/9 + 1/9 ]
= 1 - 1/3
= 2/3
= 0.667
二郎系 家系 まぜそば少し小さくなりました。ではあるノードにおいて単一のクラスのみある場合はどうでしょうか。
count = 3 3 6
p = 3/12 3/12 6/12
= 1/4 1/4 1/2
GI = 1 - [ (1/4)^2 + (1/4)^2 + (1/2)^2 ]
= 1 - [ 1/16 + 1/16 + 1/4 ]
= 1 - 6/16
= 10/16
= 0.625
二郎系 家系 まぜそば0となりました。きれいに分類できている証拠ですね。決定木のFeature ImportanceはこのGiniを用いて算出されているようです。 参考文献によると
count = 0 12 0
p = 0/12 12/12 0/12
= 0 1 0
GI = 1 - [ 0^2 + 1^2 + 0^2 ]
= 1 - [ 0 + 1 + 0 ]
= 1 - 1
= 0.00

 による分岐ノードでのImpurity Reductionの総和となっています。
による分岐ノードでのImpurity Reductionの総和となっています。つまり、対象の特徴量が木全体においてどれだけGini不純度の減少に寄与できたかという指標でFeature Importanceが算出されているということです。
ということはです。分岐点を多く作りやすい変数の方が相対的にFeature Importanceが大きくなるのは直感的ですよね。単純に考えるとカテゴリカル変数よりも連続値変数の方がFeature Importanceが相対的に高まってしまうということです。さらに木を深めることで多くの分岐点が生成されるのであればその効果は莫大です。
実際Feature ImportanceにはCardinalityが密接に関係します。次にCardinalityについてみてみます。
Cardinality
みんな大好きKaggleにおいて次のような質問があった。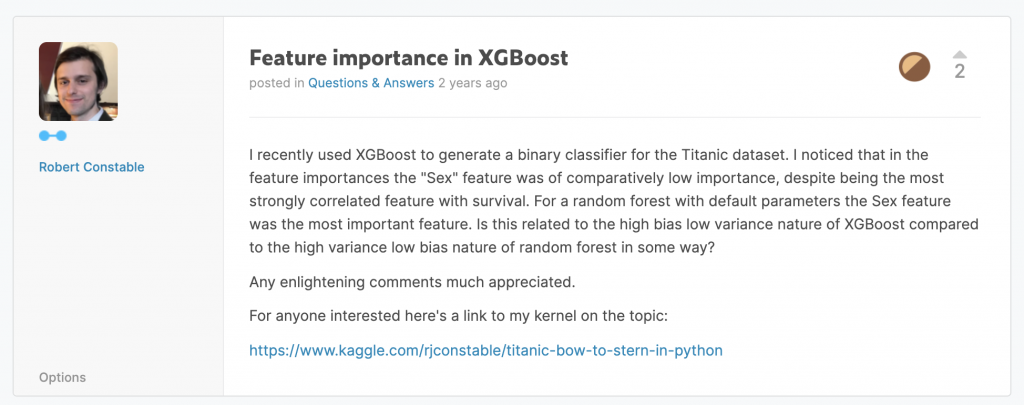
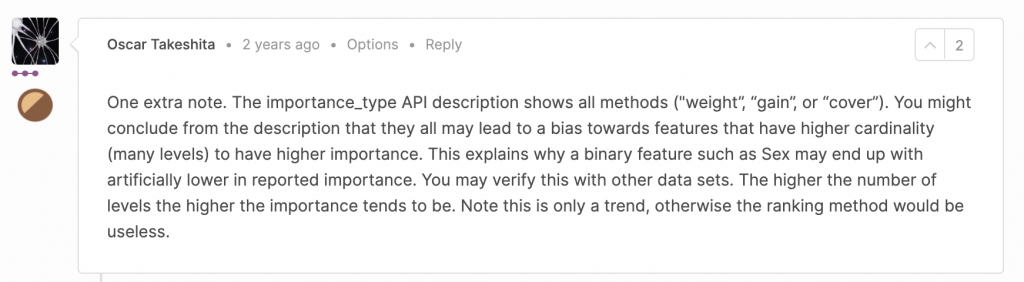
ここでカーディナリティとは、対象の変数の多様性のこと。つまり性別のようなカテゴリカル変数よりは連続値の変数の方がカーディナリティは相対的に高い。
これはまさに上記のGiniの定義より得られた考えのことだ。よってさきほどのFeature Importanceに対する理解は正しかったということだ。
Information Gain
実は決定木における重要な指標はGini Impurityだけではなく、Information Gain(平均情報量)というものが別であります。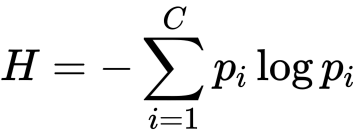
LIME
じゃあ、どうしたらちゃんとした、まともな、直感的なFeature Importanceが得られるのか。という問に対する答えは僕の知るベストだとSHAPだ。もうSHAPしかない。上述した理由から決定木におけるFeature Importanceに信憑性はない、結果的に重回帰がやはり好かれている。しかし、分類という点においては決定木やNNには重回帰では残念ながら勝てない。
最高に分類できる状態を保ちつつ、重回帰のように最高の形でFeature Importanceがほしい、という欲求を満たしてくれるのがSHAPだ。LIMEの上位互換なのでやってることはほぼ同じ。
記事の最後になりましたがここでは低次元空間においてLIMEの振る舞いを簡単に実装してSHAP(LIMEの上位互換)のイメージを理解します。下のような非線形データを考えます。


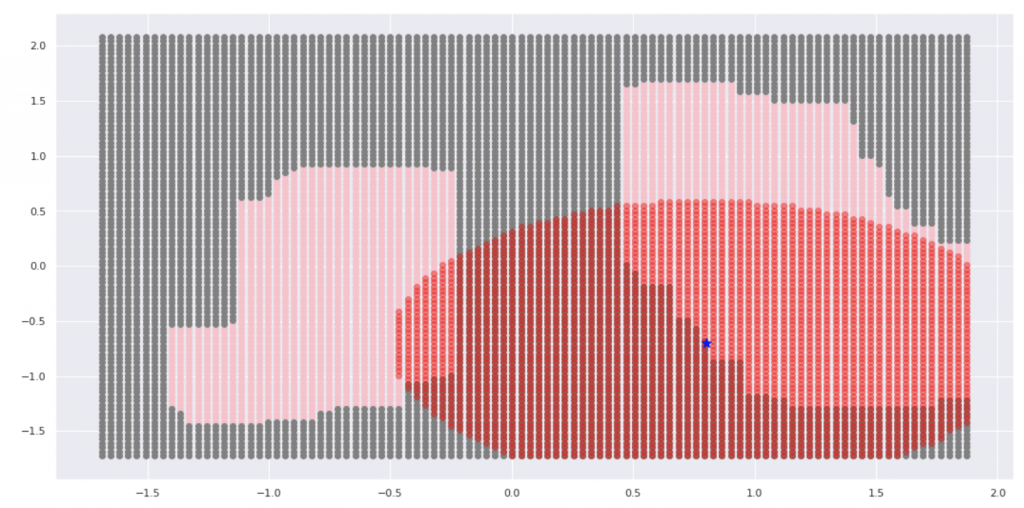
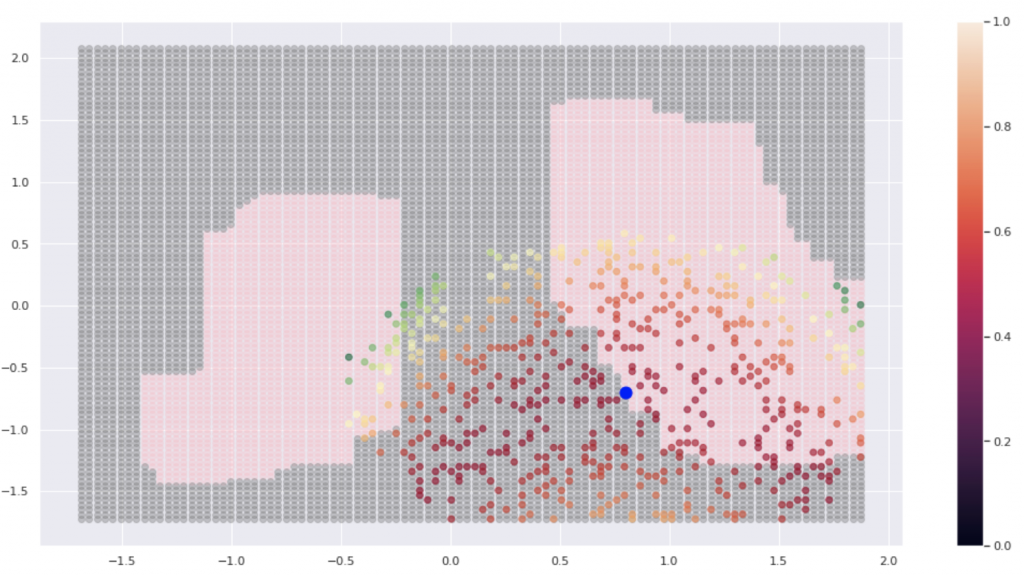

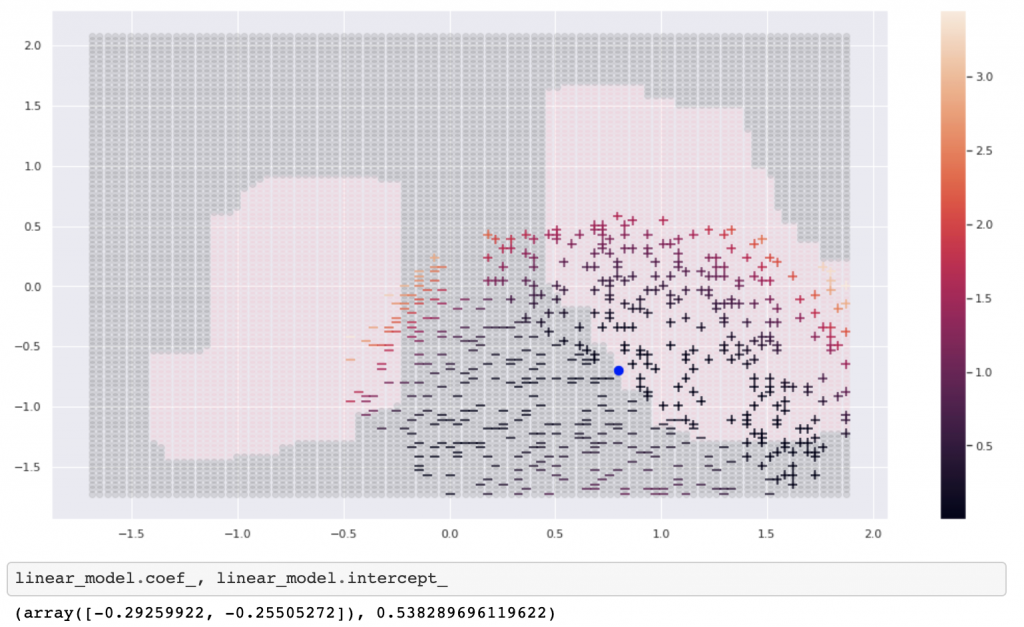
ちなみにSHAPの凄いところは制約3つめのConsistencyです。これによって対象の特徴量のFIがより重み付されます。これによって決定木におけるFIの相対的なつぶれよりも直感的なFIを得ることができます。
Reference
- https://jamesmccaffrey.wordpress.com/2018/09/06/calculating-gini-impurity-example/
- https://en.wikipedia.org/wiki/Decision_tree_learning#Gini_impurity
- https://mlcourse.ai/articles/topic5-part3-feature-importance/
- https://towardsdatascience.com/the-mathematics-of-decision-trees-random-forest-and-feature-importance-in-scikit-learn-and-spark-f2861df67e3
- https://medium.com/coinmonks/what-is-entropy-and-why-information-gain-is-matter-4e85d46d2f01
- https://datascience.stackexchange.com/questions/10228/when-should-i-use-gini-impurity-as-opposed-to-information-gain