本日はいつものように「実装しましたぁ」ではなく、「実装に失敗しましたぁ」という話になります。 こちらが論文でPRML(Pattern Recognition and Machine Learning)の作者のものです。非常に難しい。本当に難しかったです。ですがなんとかそのアルゴリズムがわかってコードも失敗しながらですが通ったので失敗談共有という形で記事にします。この記事を見て実装に成功した方がいればぜひコメントお待ちしております。
PCA
PCAを知らない方のために説明しますと Principal Component Analysis(主成分分析) と言いまして次元圧縮方法の一つです。恐らく最もポピュラー。過去にその実装の記事をあげましたのでリンクを貼っておきます。 固有ベクトルへの射影、以上です。このPCAの発展版として今回、BPCAをやります。BPCA
みんな大好き「隠れ変数」のようなものを導入します。何かと言いますと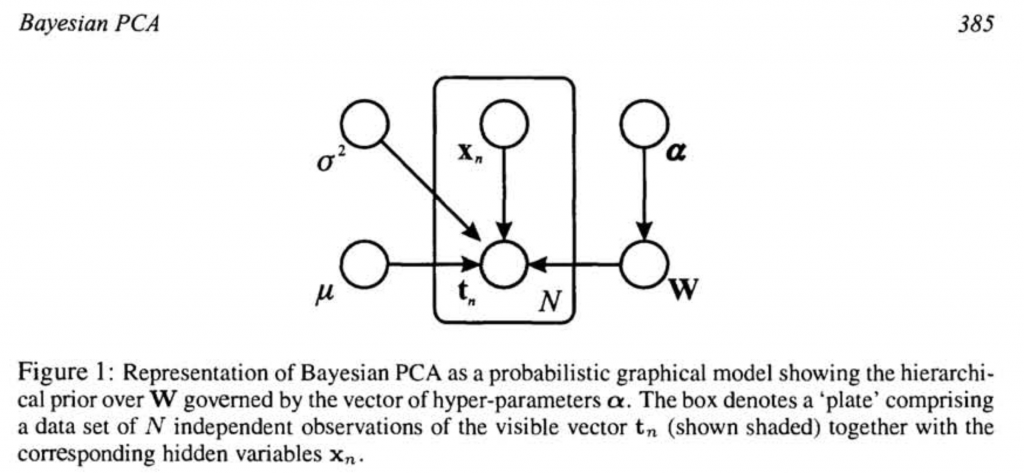
 が観測データ、
が観測データ、 が隠れ変数です。どうやって次元を削減しているかと言いますとProbablistic PCAという理論に基づいており、
が隠れ変数です。どうやって次元を削減しているかと言いますとProbablistic PCAという理論に基づいており、 の次元をそれぞれ
の次元をそれぞれ として観測値は「実はもっと小さい次元から生成されているはずであり、の線形変換+ノイズという過程を経てとして現れている」というものです。そこで論文ではガウス分布からサンプルを生成してヒントン図を用いて検証を行っています。
として観測値は「実はもっと小さい次元から生成されているはずであり、の線形変換+ノイズという過程を経てとして現れている」というものです。そこで論文ではガウス分布からサンプルを生成してヒントン図を用いて検証を行っています。ヒントン図
アレイ(行列)の成分の大小を色とブロックサイズでの可視化を試みた図です。実装編 Python
論文をベースに求める結果としては