本日は実装です。カーネルk平均法を実装します。言語はいつも通りPythonです。
Kernel K-meansとは?
非線形データのクラスタリング手法のです。前回紹介したカーネルトリックを用いてデータを高次元空間へと写し、k-meansを行います。このトリックを用いて非線形データを分離するのですが初期値に非常に依存し、時にうまく分離することができません。なので実際に使われているところは見たことないですね、、アルゴリズム
K-meansとほとんど同じです。- ランダムにcentroidをクラスタ数決める。
- 特徴空間において各データと各centroidからの距離を測る(総和D)
- 各データを最小の距離をもつクラスタに割り当てる
- STEP-2から繰り返す
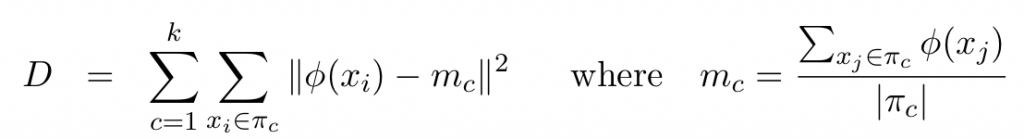
 はカーネル
はカーネル は特徴空間での各クラスタの中心
は特徴空間での各クラスタの中心 は各クラスタ
は各クラスタ は各クラスタの大きさ
は各クラスタの大きさ
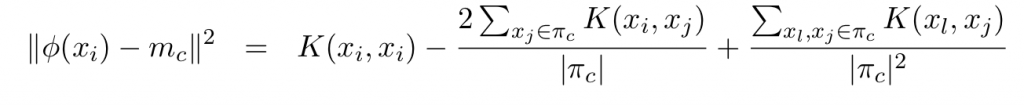 を代入すれば上記が得られます。あとはコードを書くだけです。
を代入すれば上記が得られます。あとはコードを書くだけです。